NoSQL 的学习使用和环境配置
数据库系列笔记
点击查看系列汇总:

- 数据库原理课程笔记部分:
- 手搓数据库 (CS346) 部分:
- Oracle 和 NoSQL 课程部分:
Oracle 的学习使用和环境配置- NoSQL 的学习使用和环境配置 【当前阅读】
关于 NoSQL
关系型数据库(RDBMS)的特点主要有:
- 数据的存储将独立于硬件
- 呈献给用户的则是被称为“关系”的二维表结构
- 可以通过 SQL 语句实现数据定义和操作
- 支持事务和 ACID 一致性等特性
但是关系型数据库要横向拓展成计算机集群的模式就很麻烦(主要是完整性约束和事务一致性的问题),所以就出现了 NoSQL, Not Only SQL。
NoSQL 可以看作是一些分布式非关系型数据库的统称,它们一般会弱化表的结构、完整性约束、以及(甚至于取消)事务机制,也有可能不支持完整的 SQL,但是用这些代价换来了分布式部署能力,比如分区容错性、伸缩性、访问效率等等。
列族数据库 HBase
列族数据库是面向列组织数据的 NoSQL 数据库模型,不按行把一整条记录连续存储,而是按列进行物理组织,并且允许列被分组管理。
列族本身就是列的逻辑分组和物理存储单元。同一个列族中的列通常具有相似的访问模式或生命周期,因此会被一起存储和压缩。列族在建表时就需要定义,而列族下面具体的列名可以动态增加。逻辑上一条记录看上去是一行,但是它们按照列族分开存储了,所以在读取信息时,不需要一口气读取一行,读一个列族就行了。
在列族数据库中定义一个具体的数据值需要五个维度:
- 行键: 每一行数据的唯一标识,数据在物理存储上是按行键的字典序排序的。
- 列族: 相关的列被组织在一起形成列族,是物理存储的基本单位,列族在创建表时必须预先定义好,且不宜过多。
- 列限定符: 列族下的具体列,是动态的,每一行可以有不同的列名。
- 时间戳: 数据版本标识,同一个坐标下可以存储多个版本的数据。
- 值: 最终存储的二进制数据。
在逻辑上,列族数据库(这里指 HBase)可以看作是一张稀疏的非常宽的表,因为有很多格子是 NULL,而且它们不占空间,但在物理上,HBase 中不同列族的数据存在 HDFS (Hadoop Distributed File System) 的不同文件中。每一条记录在底层其实是一条 行键 + 列族 + 列限定符 + 时间戳 → 值 的键值对。
集群架构和分布式原理
既然可以在多台机器上存数据,那系统在多台机器上分片存储、定位数据,协调节点状态,以及在性能、一致性和可用性之间做取舍就是问题了。
Apache Hadoop 是一个用于大规模数据存储和批处理计算的分布式框架,其设计目标是在廉价硬件上可靠地处理海量数据。它包含三个关键部分:
HDFS,分布式文件系统。数据被切成大块分布到多个节点,并自动复制,以保证容错性和高吞吐读取。它更像一个为顺序读写优化的海量存储层。
YARN (Yet Another Resource Negotiator),用于资源管理,它负责在集群中调度 CPU 和内存资源,让多个计算任务共享集群。
计算框架,如
MapReduce用于并行处理分布式数据,将任务拆分到各节点执行。
HBase 就是利用 Hadoop 的持久存储,把数据库能力叠加在 Hadoop 之上,与此同时,Cassandra 则选择自建完整的分布式栈,以换取更简单的部署和更低的系统耦合。它们两个也就代表了分布式数据库集群的两种架构:
- 主从式架构,以 HBase 为代表:
- 这种架构的核心思想是控制面集中,数据面分布。
HMaster负责全局视图,而数据节点只专注局部执行。 - 当一个表被创建后,系统会按行键范围把数据切成多个
Region[1]。这些Region被分配到不同RegionServer上。客户端访问时,并不是把请求交给HMaster,而是通过协调服务(比如ZooKeeper)找到目标Region的位置,然后和它进行通信。 Region会随着数据增长自动分裂。比如一个Region写满后被拆成两个新区间,再重新分配。这个机制能保证单节点负载受控,且数据能横向扩展。ZooKeeper在这里的作用是一致性的协调:它保存谁是Master、每个Region在哪台机器上,以及节点是否存活。它提供的是强一致的小规模元数据服务,而不是存储用户数据。
- 这种架构的核心思想是控制面集中,数据面分布。
- 对等架构,以 Cassandra 为代表:
- 这种架构没有中心节点,所有节点都能服务读写请求(这就叫 P2P)。
- 采用一致性哈希的工作方式,系统把整个键空间看成一个环。每个节点负责环上的一段哈希区间。客户端或驱动程序计算分区键的哈希值,就能直接定位负责节点:
- 整个哈希空间是一个 64 位的环。每个节点被分配一个或多个 Token,负责环上的一段区间。
- 新节点加入时只迁移局部数据。
- 扩容不会全量重分布
- 节点之间通过 Gossip 协议交换状态,例如节点是否在线、延迟如何。
使用 HBase
在关系型数据库中可以通过索引查任何字段,但在列族数据库中,只能高效地通过 Key 查询。
常见指令:
- 管理类:
create:建表describe:看结构alter:改列族disable/drop:禁用表之后删表
- 数据类:
put:插入或更新get:根据 RowKey 获取一行scan:范围查询,由于数据按顺序存储,范围扫描极其高效count:统计行数(在 HBase 中由于需要全表扫描,大数据量下比关系型数据库慢很多)。
HBase/Hadoop 伪分布式环境配置
这里的环境配置说明只针对 Ubuntu 20.04 2C1G 设备。
但是非常不建议使用这种性能糟糕的设备来完成这个任务,1G 内存根本扛不住这么多 JVM。
配置 Hadoop
创建 Hadoop 用户
创建用户并并给予 sudo 权限:
1 | |
切换到 Hadoop 用户:
1 | |
安装 Java 8
注意:后面 Neo4j 等需要的 Java 版本与当前不同,如果遇到了 Java 环境冲突的问题可以按照下面的思路排查。
检查:
1 | |
然后可以使用下面的解决方案:
使用
update-alternatives工具1
sudo update-alternatives --config java执行命令,可以看到一个列表,它显示了系统中所有的 Java 版本。
临时修改
JAVA_HOME,例如:1
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64 <你想要执行的命令>
1 | |
配置 JAVA_HOME
编辑用户环境变量:
1 | |
在文件末尾添加:
1 | |
生效:
1 | |
验证:
1 | |
配置 SSH 无密码登录
生成密钥,然后把公钥放在本地。
1 | |
一路回车即可,
1 | |
验证:
1 | |
防火墙配置
1 | |
如果结果是 inactive,那就可以了。也可以按需放行相关端口,方便看 Web UI,记得在云服务商那里也进行修改。
1 | |
Hadoop 安装
下面的步骤都需要当前用户是 hadoop:
1 | |
下载并解压:
1 | |
配置 Hadoop 环境变量
编辑 ~/.bashrc:
1 | |
追加:
1 | |
生效:
1 | |
验证:
1 | |
能看到 2.7.7 即成功。
配置 Hadoop 使用 Java 8
这一步非常关键:
编辑:
1 | |
找到或添加:
1 | |
让修改生效,或再开一个新的 shell:
1 | |
配置核心 XML 文件
XML 文本中的数据可以酌情更改。
core-site.xml1
vi $HADOOP_HOME/etc/hadoop/core-site.xml替换成:
1
2
3
4
5
6<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml(对当前服务器进行了专门优化,但收效甚微)1
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml替换成:
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>localhost:9000</value>
</property>
</configuration>mapred-site.xml1
2
3cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template \
$HADOOP_HOME/etc/hadoop/mapred-site.xml
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml编辑:
1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml1
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml编辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>512</value>
</property>
</configuration>
格式化 HDFS
这部分只做一次:
1 | |
看到 successfully formatted 即可。
启动 Hadoop 伪分布式
1 | |
如果没有报错就是成功。
验证 Hadoop 运行
执行:
1 | |
至少应该看到:
NameNodeDataNodeSecondaryNameNodeResourceManagerNodeManager
配置 HBase
HBase 安装
下载 HBase 2.2.6:
1 | |
配置 HBase 环境变量
编辑 ~/.bashrc:
1 | |
追加:
1 | |
生效:
1 | |
验证:
1 | |
应显示 2.2.6。
配置 HBase 使用 Java 8
1 | |
找到或添加:
1 | |
配置 hbase-site.xml
1 | |
编辑:
1 | |
让 HBase 连接 Hadoop 配置
1 | |
不拷这两个文件,HBase 会连不上 HDFS。
启动 HBase
1 | |
第一次启动会稍慢。
启动完成后验证:
1 | |
在原有 Hadoop 进程基础上应额外看到:
HMasterHRegionServerHQuorumPeer(ZooKeeper)
进入 HBase Shell:
1 | |
依次执行:
1 | |
能看到数据,即成功。
退出:
1 | |
使用 Docker 配置 Hadoop/HBase 环境
如果服务器带不动的话,也可以用 Docker 而不是虚拟机在本机运行。
博主自己配置了相关的 Dockerfile,可以访问 GitHub 获取源码。
或直接从 Docker Hub 拉取镜像:
1 | |
使用步骤可以参考其中的 README 或 Overview。
文档数据库 MongoDB
MongoDB 是一种面向文档的 NoSQL 数据库,它的核心设计目标是用接近应用对象结构的方式存储数据,同时保证高吞吐写入和可扩展持久化。它的基本单位不是行,而是文档。文档本质上是一组键值对,但是它允许嵌套结构,因此可以自然表达层级数据,这种结构与应用中的对象模型接近,减少了关系型数据库中的表拆分和 join 操作。例如:
1 | |
多个文档可以组成集合。集合不像传统表那样强制统一模式,同一个集合中的文档可以字段不同:
1 | |
数据库本身不会拒绝这种差异。这种“模式自由”意味着:
可以逐步演化数据结构
减少迁移成本
但代价是需要应用层或验证规则保证数据一致性。
BSON 存储模式
MongoDB 在内部使用 BSON (Binary JSON) 存储文档。BSON 的设计目标是:
- 支持更多原生类型(时间、二进制、64 位整数等)
- 高效序列化与遍历
与文本 JSON 不同,BSON 是长度前缀[2]的二进制结构,因此数据库可以快速跳过字段而不必逐字符解析,这对高频读写非常重要。
每个文档必须包含 _id 字段,默认值是 ObjectID。ObjectID 的结构体现了分布式设计思想:
- 时间戳部分保证近似递增顺序
- 机器与进程信息减少冲突
- 计数器确保同一时间内唯一
所以,在多节点环境中,无需中央 ID 服务也能生成全局唯一键,同时插入顺序基本按时间排列,有利于索引局部性。
MongoDB 的索引
MongoDB 通过索引显著提高查询效率,默认会自动为 _id 建立索引。支持对:
- 单个字段索引
- 复合字段索引(关键原则:左前缀原则)
- 多键索引:面向数组内容的搜索
- 全文索引:面向字符串的搜索
- 地理位置索引
- 2d 索引:用于平面坐标查询
- 2dsphere 索引: 用于球面(地球坐标)查询
同时,MongoDB 也引入了索引属性以进行约束和查询策略优化:
- 唯一索引在插入或更新时强制检查键值是否重复。这相当于数据库级别的约束,适合用户名、邮箱等字段。代价是写入路径必须多一次冲突检测。
- 稀疏索引只记录包含该字段的文档。
复制集
MongoDB 也可以建立在不同的机器上,复制集解决的问题就是机器坏了怎么办。
一个复制集本质上是多节点维护同一份数据的多副本系统,主要有三大角色:
Primary是唯一写入口,所有写操作都会被记录为一条操作日志(Oplog)Secondary节点持续拉取这些操作日志,然后异步本地重放,它们的数据是主节点的延迟副本Arbiter,稍后再说
这是一种操作复制模型,而不是直接复制数据文件。好处是:
- 网络传输量小
- 可以保持写入顺序一致
这些角色分工是为了支撑自动故障转移机制。成员间每 2 秒发送一次心跳,如果 Primary 节点 10 秒内没响应,就说明它挂掉了,所有其他节点都会比较谁数据最新与谁优先级更高,选出一个新的来。Arbiter 的唯一作用是在这个时候,如果出现投票平局,它就来参与投票把死锁破除掉。
除了这几个角色,还有两个特殊节点:
Hidden:隐藏节点,优先级为 0,对客户端不可见。用于离线备份或报表计算。Delayed:延迟节点,强制落后主节点一段时间(如 1 小时)。用作后悔药,防止误删数据后同步到所有节点。
分片
复制集解决的是“可靠”,分片解决的是“装不下”的问题。当单机磁盘或吞吐到达极限,就需要把不同的数据分散到不同机器。MongoDB 的分片系统做的事情也就是分布式的存储:
- 把集合拆成多个数据区间
- 分布到多个分片(Shard)
- 自动路由请求
Shard 通常本身就是一个复制集,因此每个数据分区仍然具备高可用能力。用户不知道数据存放在哪,所以需要 Mongos 路由服务器,它是无状态的,只负责查询转发。
分片策略则以片键作为数据拆分的依据。主要有两种方案:
- 范围分片: 根据片键的值范围划分,这样范围查询效率极高,但容易产生写热点(比如片键是自增 ID 或时间戳)。
- 哈希分片: 对片键进行 Hash 后划分,写操作分布极其均匀,但无法进行高效的范围扫描。
但和 Hadoop 不同,MongoDB 注重的是低延迟读写、动态扩展和实时应用访问,而前者更注重高吞吐而非低延迟和大容量的数据处理。
若干使用问题
聚合框架
MongoDB 的基本操作就是 CRUD,而且文档结构是自由的,可以嵌套数组和对象。但现实系统往往不仅是“取出数据”,还需要统计、汇总、变形等,这就需要聚合框架。
聚合框架/聚合管道可以理解为把数据处理逻辑交给数据库执行,而不是把大量数据拉回程序再计算。一条典型的聚合流程是:
$match:先过滤无关数据(相当于WHERE)$project:只保留或重组需要的字段$group:做统计,比如求和或计数$unwind:把数组拆成多条记录$lookup:跨集合关联数据
就是个流水线,但是可以减少网络传输,并且利用数据库的优化执行。
定长集合
普通集合适合长期保存数据,但某些场景是只关心最近的数据,比如日志等等。而定长集合的思想,就是:数据空间是一定大小的,新数据写入时,如果空间满了,就自动覆盖最旧的数据。
它本质上是数据库级别的循环缓冲区,非常适合时间序列数据,而不需要手动清理历史记录。
MongoDB 环境配置
安装:
1 | |
启动服务:
1 | |
可以检查运行状态确认是否成功:
1 | |
若看到 active (running),说明服务已经正常运行。
进入 Mongosh 测试连接,Mongosh 相当于 MongoDB 的前端,而 Mongod 服务就相当于后端:
1 | |
没有报错就表示安装完成。
使用 Docker 配置 MongoDB 环境
键值数据库 Redis
键值数据库的核心思想是:通过唯一的 Key 直接定位 Value。
系统内部通常用哈希表组织 Key,因此在理想情况下查找复杂度是 。与关系型数据库相比,它没有复杂的表结构、关联查询或多表事务,设计目标是极低延迟和极高吞吐。
键值数据库以 Redis 为代表,它是典型的数据结构服务器。和传统 KV 数据库不同,它的 Value 不是简单字节串,而是内置多种数据结构,这一点决定了它不仅仅是缓存,而是可编程的数据容器。
Redis 的高性能主要来自两个方面:
- 内存驻留。数据主要在内存中,避免磁盘 I/O。一次查找本质是一次哈希计算和一次指针访问。
- 单线程事件驱动。命令串行执行,没有锁竞争。配合 I/O 多路复用机制,使其在高并发下仍然稳定。
简单动态字符串
Redis 没有直接使用 C 语言原生的字符串(以 \0 结尾的字符数组),而是设计了简单动态字符串(SDS, Simple Dynamic String) 结构。
C 语言原生字符串依赖 \0 作为结束标志,因此:
- 需要遍历才能得到长度
- 无法安全存储二进制数据
SDS 在结构中显式保存长度(len)和剩余空间(free),因此:
- 读取长度是
- 可以安全存储任意字节
- 修改字符串时减少
realloc次数
这类设计说明 Redis 更像是一个专门优化过的内存数据库内核,而不是简单使用标准库结构。
Redis 的数据结构
String 字符串
这是最基本类型,一个 Key 对应一个 Value。最大存储 512MB。
它支持原子性操作,也就是支持 INCR(增 1)、DECR(减 1)等原子计数操作,这是实现分布式锁和计数器的基础。
List 列表
它是简单的双向链表,支持双向操作,也就是可以在头部(LPUSH)或尾部(RPUSH)插入。
BLPOP / BRPOP 命令具有阻塞特性:如果列表为空,客户端会进入阻塞状态直到有新元素进入。这是实现轻量级消息队列的核心逻辑。
Hash 散列
它意味着键值对内部又是一个 Map(字段 field 值 value)。
极其适合存储对象(如用户信息)。相比于将整个对象序列化为 String,Hash 可以只更新对象的某个字段(如 HSET user:100 age 25)。
Set 集合
它是无序的、唯一的字符串集合。基于哈希表实现,复杂度 。
支持集合运算: SINTER(交集)、SUNION(并集)、SDIFF(差集)。
ZSet (Sorted Set) 有序集合
这种集合中,每个成员关联着一个 Double 类型的分数(Score)。 集合内的成员是唯一的,但分数可以重复。Redis 根据分数从小到大排序。
适用于排行榜、带权重的队列。
Stream 流
Redis 5.0+ 引入的数据结构,类似 Kafka 的持久化消息链表。
消费者组 (Consumer Group): 支持多个消费者协作,记录消费偏移量(Offset),确保消息不丢失且不被重复消费。
持久化方案
虽然 Redis 是内存数据库,但它提供了两种互补的持久化方案。
RDB (Redis Database) 快照方式
在指定时间间隔内,将内存中的全量数据生成一个压缩的二进制文件 (dump.rdb)。
然后,通过 bgsave 机制:Redis 会 fork() 一个子进程。子进程负责把数据写到临时文件,最后替换旧文件。fork() 时子进程共享父进程内存。只有当父进程修改数据时,操作系统才会复制该页数据。这保证了在持久化时,Redis 仍能处理写请求且不占用双倍内存。这就是 COW (Copy-On-Write) 技术。
AOF (Append Only File) 日志方式
记录服务器收到的每一个写命令,以追加的形式写入文件。
同步策略有:
always:每次写命令都同步(最安全,最慢)everysec:每秒同步一次(默认,性能与安全的折中)
AOF 文件过大时,Redis 会根据内存现状重写一份最小指令集的 AOF。例如,对同一个键的 100 次 INCR 会被重写为一条 SET。这就是 AOF 重写 (BGREWRITEAOF)。
Redis 的管理、安全与事务
键管理与过期策略
可以为 Key 设置过期时间 TTL (Time To Live) 。
有两种清除 Key 的策略:
- 惰性删除:访问
Key时才检查是否过期,过期则删除。 - 定期删除: 每隔一段时间抽取一部分设置了过期的
Key进行检查。
事务
命令主要有:
MULTI:开始EXEC:执行DISCARD:放弃
Redis 事务本质上是将命令放入队列一次性顺序执行。
注意: Redis 事务不支持原子性回滚。如果队列中某条指令执行失败,后续指令仍会继续执行。
关于 Lua 脚本
Lua 脚本在 Redis 中执行时是原子的,所以可以将复杂的业务逻辑封装在脚本中发送给 Redis,减少网络往返,同时保证操作不会被其他命令打断,有效弥补了原生事务无法回滚的不足。
配置 Redis
安装:
1 | |
在 Ubuntu 中,Redis 安装后默认会自动启动一个系统服务。可以先停止默认服务,然后手动用配置文件启动:
1 | |
关于配置文件,一般可以单独复制出来修改一份:
1 | |
例如:
daemonize no修改为daemonize yes(允许后台运行)。bind 127.0.0.1如果需要远程访问,改为0.0.0.0,注意安全。port 6379默认端口,保持不变即可。
Redis 操作
一旦服务启动,就可以使用 redis-cli 进入交互模式。
1 | |
关闭 Redis:
1 | |
图数据库 Neo4j
关系型数据库擅长处理结构化实体的内部属性,但在处理实体间的复杂关联时,必须通过外键和多表连接来实现,当关联达到三层、四层甚至更多时,它需要进行大规模的索引扫描和内存在位连接,性能会呈指数级下降。
图数据库解决的是这个结构性问题,核心思想是把关系直接存储为物理连接,它的典型代表是 Neo4j。
如果底层借用的是键值或文档数据库存储图,那么在遍历时仍需依赖全局索引,这就叫非原生图存储。
而 Neo4j 采用的是免索引邻接,也就是说在原生图存储中,每个节点内部直接保存指向其相邻关系或节点的指针。遍历邻居时,不需要全局索引查找,只需要顺着指针跳转。
因此:
这使图数据库在深度遍历场景下性能非常稳定
属性图模型
图数据库的数据组织由四个核心要素构成:
Vertex / Node 节点
也就是业务领域中的实体(如:人、电影、银行账号)。每个节点都有一个全库唯一的、由系统自动生成的整数 ID。
Edge / Relationship 关系
关系必须有起始节点、终止节点以及方向(出边或入边),但在查询时可以忽略方向。一个关系有且仅有一个“关系类型”。
Property 属性
采用 Key-Value 形式存储。
节点和关系都可以拥有属性。属性模式是“自由且不固定”的,同一个标签下的两个节点可以拥有完全不同的属性。
支持基本类型(boolean, byte, short, int, string 等)及其组成的数组。
Label 标签与 Type 关系类型
标签用于对节点分类(类似关系型数据库的表名)。一个节点可以拥有零个或多个标签(例如一个节点既可以标记为 :Person 也可以标记为 :Actor)。
关系类型用于定义连接的性质(例如 [:WORKS_FOR])。
Path 路径
路径是由起始节点、终止节点以及中间经过的所有边和关联节点组成的序列。路径长度定义为包含的“边”的数量。
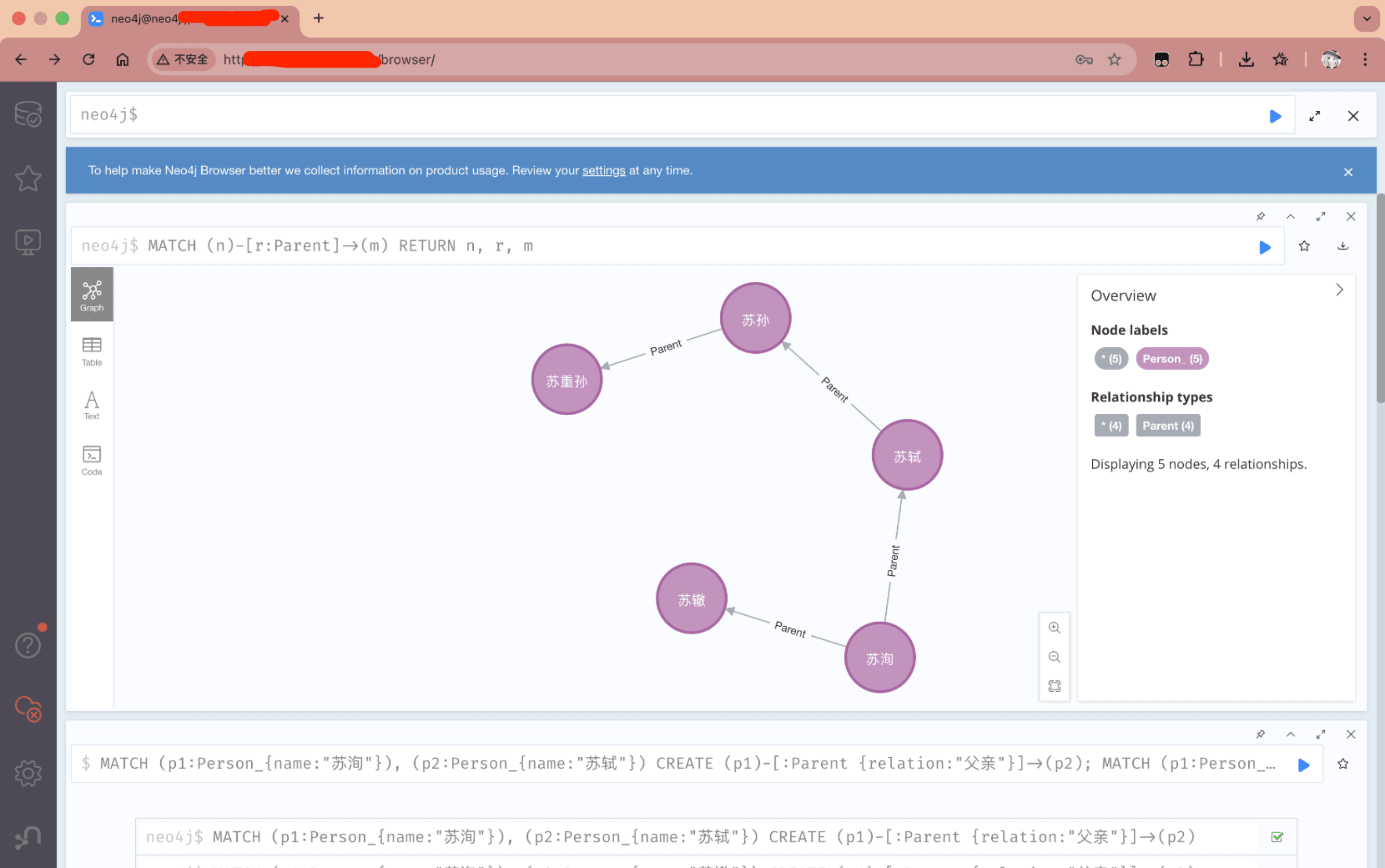
Cypher (CQL)
Cypher 是一种声明式的模式匹配语言,其核心逻辑是用 ASCII 字符画图。
语法符号
( ):代表节点。例如(p:Person)表示变量名为p、标签为Person的节点。[ ]:代表关系。例如-[r:FRIEND_OF]->表示变量名为r、类型为FRIEND_OF的有向关系。{ }:代表属性过滤或定义。例如(n{name: "张三"})。
操作指令
MATCH:核心查询子句,定义要在图中匹配的拓扑模式。WHERE:对匹配到的结果进行逻辑过滤。RETURN:指定返回的内容(点、边、路径或特定属性)。CREATE/MERGE:CREATE直接创建。MERGE具有幂等性,检查模式是否存在,不存在则创建,存在则匹配。
SET/REMOVE/DELETE:SET:添加或更新属性/标签。REMOVE:删除特定属性或标签(节点还在)。DELETE:彻底删除节点或关系。- 若节点有关联关系,必须先删关系或使用
DETACH DELETE。
路径遍历与变长路径
图数据库最强的功能在于处理不确定长度的关联。
- 语法:
-[*min..max]->。 - 例如:
(a)-[*1..4]-(b)表示查找a到b之间1到4层深度的所有路径。
Neo4j 的高级功能和系统管理
事务
Neo4j 是完全支持事务的,支持 ACID 性质。
索引
Neo4j 可以在特定标签的属性上建立索引(如 CREATE INDEX ON :Person(name)),用于加速 MATCH 定位起始点的过程。
约束
Neo4j 支持唯一约束,可以强制某个标签的属性值唯一(如 ASSERT p.id IS UNIQUE)。
配置 Neo4j
首先需要安装 JDK 17,注意和其他数据库的版本不同:
1 | |
下载 Neo4j:
1 | |
启动:
1 | |
配置远程访问
服务器没有图形界面,所以一般需要从你自己的本地设备通过浏览器访问服务器的 7474 端口,它会在该端口启动一个浏览器页面。
首先修改配置文件:
1 | |
找到下面这一行,把前面的 # 号删掉以取消注释:
1 | |
保存并退出,然后重启 Neo4j:
1 | |
然后打开防火墙端口:
1 | |
如果采用的是服务商的服务器,则也需要到服务商那里打开 7474 和 7687 端口,选用 TCP 协议。
如果使用的是 Azure 服务器,那么微软官方已经提供了 Neo4j 的预设,直接选择即可。