机器学习 课程笔记
写在前面
2025/12/09 更新:
12 月 2 日考完机器学习,现在有点空,更新一下。
考完的时候和饭哥等群友复盘了一下 23 级考试的原题,可以点击这里观看饭哥的汇总,希望将来我们也可以把考题传承下去。
总的来说,23 级考题从难度上比 22 级高了不少,考的很细很偏,计算题难度也提升了,但也没有特别困难的公式推导(KKT 条件这种肯定不会涉及到)。总结一下就是,BFS 的复习思想是不能丢掉的,具体也可以看看上面的汇总。
这是吉林大学 2023 级机器学习 B 课程的复习/预习/应试笔记,本门课的授课顺序是比较混乱的,于是我基于机器学习方法调整了一下笔记各部分的顺序:
- 绪论
- 监督学习
- 线性回归
- 逻辑回归
- 支持向量机
- 无监督学习
- 降维
- 聚类
- 深度学习
常见网络模型(本章节只有 2022 级教案有,2023 级教案不存在这部分内容)- 神经网络
- 径向基函数网络(2022 级教案中这章同时包含了径向基函数和自组织特征映射神经网络)
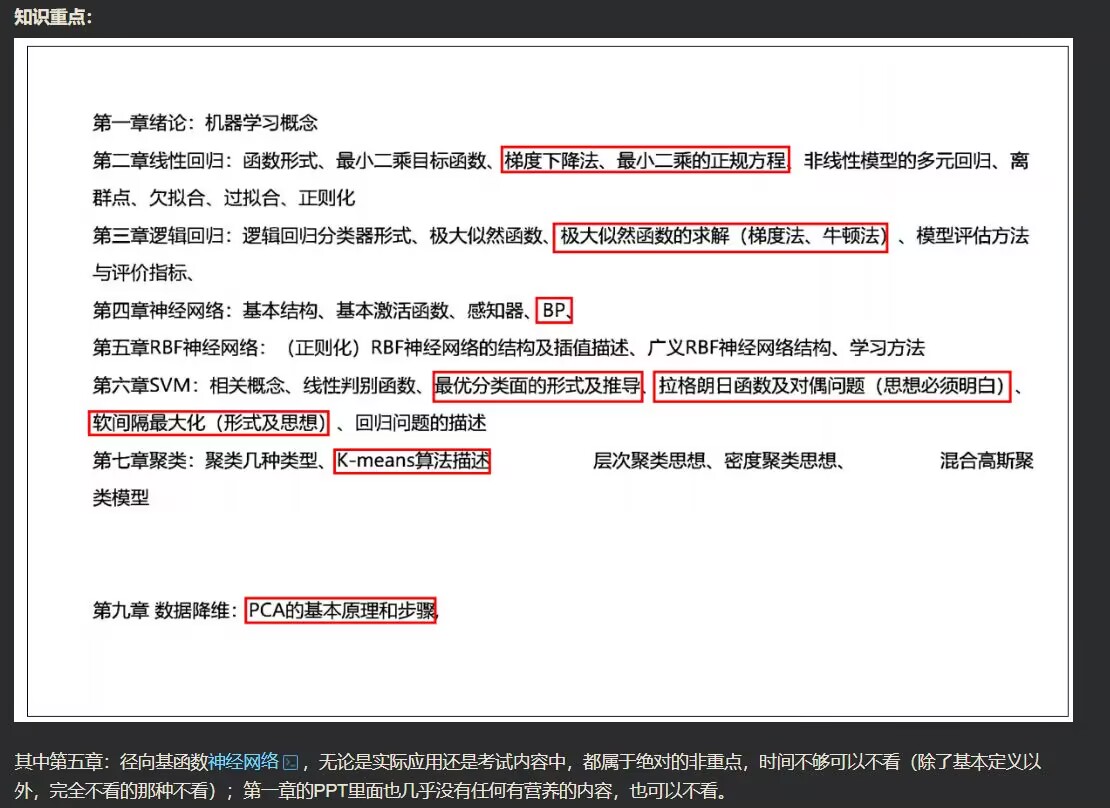
关于考试范围,在笔记中不重要的章节,博主也已经在上面和文档中的标题中用斜体标注了它的标题,重点部分用粗体标出。
考试同时也不涉及复杂的公式推导,只要背下来公式,并知道如何计算即可。需要记住的公式已用 \boxed 标记出,例如:
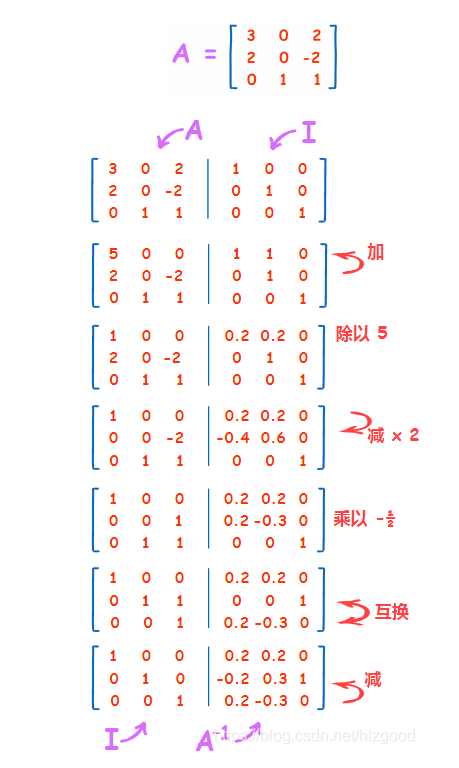
矩阵微积分和矩阵求逆
矩阵微积分公式:
矩阵求逆方法(高斯-若尔当方法):
绪论
机器学习的定义:
A computer program is said to learn from experience with respect to some task and some performance measure , if its performance on , as measured by , improves with experience . (Tom Mitchell, 1998)
机器学习 = 随着经验 的增加,完成任务 的表现 持续变好。
机器学习就是要寻找一个函数
我们希望从数据中学习一个映射:
其中:
- :输入空间(特征)
- :输出空间(标签)
训练集的数学表示:
其中,
:样本数量
每个样本由两部分组成:
- :第 个样本的特征
- :第 个样本的标签
训练的目标就是在训练集上学习一个函数:
机器学习的基本流程
机器学习整体流程非常固定,可分为三大步:
选择模型
选择一个模型(定义函数集合)等价于选择一个函数族:
例如:
线性回归:
神经网络:网络结构决定函数族的形状
SVM:决策边界的形式由模型选择决定
定义目标函数
即定义损失函数/似然函数/正则项,目标函数通常称为 或 。
下面按类别总结。
分类常用损失
- 0-1 损失(注:不可导,不用于训练,只用于评估。)
- 交叉熵损失(最常用),二分类:
回归常用损失
- 均方误差(MSE),光滑,可导,最常用。
- 平均绝对误差(MAE),抗离群点能力强。
- Huber 损失,结合 MSE 和 MAE 的优点。
概率推理相关损失
- KL 散度(常用于 VAEs)
- 最大似然(MLE)
目标是最大化似然:
等价于最小化负对数似然 NLL:
正则化(避免过拟合)
- L1 正则,使参数稀疏。
- L2 正则,使参数变小(权重衰减)。
- 范数约束
选择最优函数(训练 = 优化)
最常用方法:梯度下降。
其中:
- :学习率
- :目标函数
梯度下降是一个迭代求解最小值的过程。
随机梯度下降(SGD)每一步只使用一个样本或小批量样本:
优点:
- 更快
- 可以在线学习
- 适合大规模数据
机器学习的主要类型
监督学习(Supervised Learning)
利用带标签数据学习一个映射 。
任务:
- 分类
- 回归
关键点:
- 标签真实、明确
- 训练目标:拟合标签
半监督学习(Semi-supervised Learning)
结合少量标注 + 大量无标注数据。
两大基本假设:
聚类假设:同一聚类中的样本倾向于有相同的标签
流形假设:数据分布在低维流形上,局部相似 → 标签相似
无监督学习(Unsupervised Learning)
没有标签,从数据中发现结构。
任务:
- 聚类(k-means、层次聚类)
- 降维(PCA、LDA)
- 密度估计
强化学习(Reinforcement Learning)
Agent 与环境交互,通过累积奖励学习策略。
强化学习不是“靠标签”,而是凭 trial-and-error 学习。
| 类型 | 如何学习? |
|---|---|
| 监督学习 | 给定正确答案(指导) |
| 强化学习 | 给定奖励(好/坏),但没有对错标签 |
自监督学习(Self-supervised Learning)
从无标签数据中自动构造标签来训练模型。
例子:
- BERT:预测被 mask 的词
- GPT:预测下一个词
- SimCLR:预测不同视角的相似性
Yann LeCun:
如果人工智能是一块蛋糕,蛋糕的大部分是自监督学习,糖衣是监督学习,樱桃是强化学习。
- 意思:自监督学习未来最重要。
线性回归
监督学习概述
监督学习的任务类型:
- 回归(Regression):输出是连续值,如房价预测、温度预测。
- 分类(Classification):输出是离散类别,如图片识别、垃圾邮件分类。
监督学习的一般范式:
训练集形式:
- : 维特征( 是代表第几个数据的序号,这个 是一个向量!)
- :输出(回归时)或类别(分类时)
线性回归模型(Hypothesis)
给定 个特征,线性回归假设模型为:
是参数(权重),需要从数据中学习。写成向量形式:
若将 扩展为:
则上式成立。
确定
我们需要一个 代价函数 (cost function)来衡量 与真实 的误差。
从样本数据推导损失函数:
- 原始误差表示:绝对误差()
直观、可解释,但:
- 不可导(在 0 点不可导)
- 优化困难
- 更常用:平方误差()
为了可导且数学简单,我们改为平方误差:
常见形式会加入 [1]:
因此我们可以得到最小二乘目标函数(Least Squares),也就是我们最终要优化的目标:
目标:找到能让模型预测接近真实 的参数 。
线性模型的特点
- 形式简单
- 可解释性强( 的大小反映特征的重要性)
- 是许多非线性模型的基础
- 深度模型可以被看作线性模型的堆叠
特征规范化(Feature Normalization)
也叫做归一化。也就是把用于将数据的特征缩放到相同的范围内。其目的是消除不同特征之间的量纲差异,使得每个特征在相同的尺度上进行比较。
如果不同特征量级差别巨大:
- 代价函数的等高线变得“狭长”
- 梯度下降效率极低
因此需要归一化,例如 Z-Score 标准化,将特征转换为标准正态分布:
解释:
- 减去均值:让数据居中
- 除以标准差:让尺度一致
作用:
- 提高模型性能:许多机器学习算法,尤其是那些基于距离的算法(如 K 近邻算法、SVM 等),对数
据的量纲非常敏感。不同特征的量纲差异可能导致某些特征在计算距离时占据主导地位,从而影响
模型的性能。归一化可以消除这种量纲差异,使得所有特征在同一尺度上进行比较。 - 加速收敛:对于基于梯度下降的优化算法(如线性回归、逻辑回归、神经网络等),特征归一化可
以加速算法的收敛过程,提高模型训练的效率。 - 增强可解释性:归一化后的数据特征具有相同的尺度,更容易进行可视化和解释。
正规方程解法
就是直接给出 的闭式解(closed-form solution)[2],计算出所需的 。
构造矩阵 和向量
训练样本:
令:
用矩阵表示目标函数
首先:
因此:
平方和误差可以写成:
取导数:
令其 :
最终解为:
条件: 可逆。
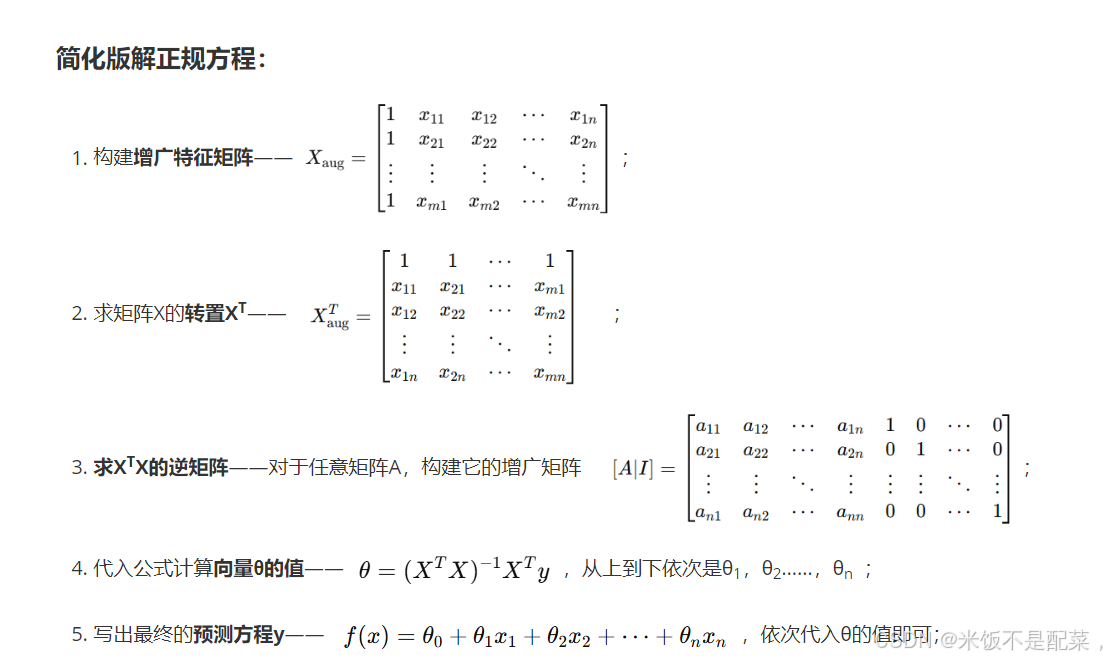
梯度下降法解法
梯度下降法(Gradient Descent)是用来 最小化 一个目标函数 的最常用方法。
直觉上:
- 梯度(gradient)表示函数上升最快的方向
- 因此最陡下降方向是其反方向
所以我们更新参数的方法是:
其中:
- :学习率(step size)
- :梯度
- 注意符号
如果不是要“下山”,而是要“爬山”(最大化):
梯度是指向上升最快方向的向量
- 要最大化 → 顺着梯度走
- 要最小化 → 逆着梯度走
梯度的数学意义
函数 的梯度是:
它代表在点 处函数上升最快的方向。
假设只有一维参数 ,损失函数 :
- 如果导数为正 → 表示在右边函数变大 → 要往左(减小 )
- 如果导数为负 → 要往右(增大 )
这就是梯度向下的最直观思想。
线性回归的梯度推导
这是针对线性回归目标函数的梯度推导,对于单个样本:
损失函数(单样本):
计算偏导:
因此更新规则(单样本):
这也叫 LMS(Least Mean Square)更新规则,也就是梯度下降在线性回归里面的专有名字。
LMS 规则有什么用?观察更新量:
这告诉了我们它是如何调整参数的:
- 误差驱动:
- 如果预测准了,误差很小,参数就不动
- 如果误差很大,更新的步子就迈得很大
- 这是一种自适应机制,离目标远时跑得快,离目标近时走得慢。
- 输入加权:
- 为什么要乘 ?
- 如果某个特征很小(比如接近0),说明这个特征对预测结果没啥贡献
- 既然没贡献,这次预测出错了,也不该怪到 头上,所以更新得很少
- 如果 很大,说明这个特征对结果影响大,预测错了它有很大责任,所以要大幅调整
- 可以起到责任分配的作用,谁的输入大,谁的权重就改得多
LMS 非常适合在线学习,因为只需要一个样本就能更新,数据来一个学一个,不需要等所有数据到齐。这非常适合实时系统(比如实时股价预测)。
梯度下降求解的三种形式
- Batch Gradient Descent(批量梯度下降)
每次用所有样本的平均梯度:
特点:
- 每次更新很“准”,但速度慢
- 大数据集时很低效
- Stochastic Gradient Descent(随机梯度下降)
每次只用一个样本:
特点:
- 更新频繁 → 收敛快
- 会震荡,不会到精确最小值,但会接近它
- Mini-Batch Gradient Descent
折中方法:每次用 个样本(如32、64、128)。
优点:
- 稳定
- 高效
- GPU 适配
目前深度学习里最常用。
线性回归损失是凸函数
这部分证明线性回归的损失一定只有一个全局最优。
线性回归损失:
是一个 二次函数(quadratic function),对应一个“碗形”:
- 凸函数(convex function)
- 只有一个全局最小值,没有局部最小值
所以梯度下降一定能找到全局最优。
关于学习率 的讨论
如果 太小:
- 每一步走很慢,收敛慢
如果 太大:
- 跨过“山谷”,震荡甚至发散
解决方法:
现代优化算法使用动态学习率:
- Adagrad
- RMSProp
- Momentum
- Adam(RMSProp + Momentum)
Adam 最常用。
梯度下降和正规方程的对比
| 项目 | 梯度下降 | 正规方程 |
|---|---|---|
| 是否需要学习率 | 需要 | 不需要 |
| 是否需要迭代 | 是 | 否 |
| 是否需要特征归一化 | 需要 | 不需要 |
| 时间复杂度 | ,需要计算逆 | |
| 特征数量大时 | 可用 | 不可用 |
正规方程缺点:
- 需要矩阵 ,可能不可逆
- 特征维度大时,求逆非常慢
所以实际工程中基本不用正规方程,深度学习完全都用梯度方法。
线性回归的概率解释
线性回归假设数据满足:
其中:
- 独立同分布
- 服从高斯分布
为什么服从高斯?中心极限定理:很多随机因素叠加会接近正态分布。
最小二乘 = 最大似然估计(MLE)
若误差为高斯分布,那么最大化似然就是最小化平方误差和,这是因为高斯分布概率密度:
要最大化似然,就是要最小化上式指数的负号部分:
这部分可以证明:
在高斯噪声假设下,最小二乘法是最大似然估计(MLE)得到的最优解。
即:
- 假设噪声 ~
- 写出似然函数
- 对数化
- 最大化似然
- 得到与最小二乘 完全等价
这个证明的意义是:
线性回归不仅仅是数学上的“平方误差最小”,而是统计意义上的 最优无偏估计。
这让线性回归有了非常强的理论基础。
线性回归的拓展
局部加权线性回归
普通线性回归给每个样本同等权重,而 局部加权线性回归(Locally Weighted Linear Regression, LWR)会根据预测点 的邻近程度,对样本赋予不同的权重 :
- 距离近 → 权重大
- 距离远 → 权重小
直观理解:我们希望“关注局部”,即预测时主要用邻近点的信息,而不是全局平均。
带权重的平方误差函数:
- :回归系数
- :样本 的权重
矩阵形式:
求解方法:
令偏导数为 0:
得到 加权正规方程:
求解参数:
与普通正规方程类似,只是加入了权重矩阵 。
权重选择
最常用的是 高斯核函数:
- :训练样本
- :预测点
- :控制“局部性”的参数
- 大 → 权重差异小 → 更像全局回归
- 小 → 权重差异大 → 只使用附近点
直观:预测点周围的点“更重要”,远的点几乎不参与。
非线性模型的多元回归
线性回归可以扩展到非线性特征,通过 特征变换:
- 可以是多项式、正弦、指数等函数
- 保留线性回归解法,只是特征被非线性映射
损失函数:
矩阵形式:
- 是映射后的特征矩阵
- 与普通线性回归求解方法相同
直观理解:线性回归“只对参数线性”,特征可以非线性 → 可拟合复杂关系。
机器学习中的若干讨论
样本离群点(Outliers)
极端值可能严重影响线性回归结果
对应方法:鲁棒回归(robust regression)、使用 损失
欠拟合与过拟合
欠拟合(underfitting):模型太简单,对训练数据拟合不好
过拟合(overfitting):模型太复杂,对训练数据拟合好,但泛化差
奥卡姆剃刀法则(Occam’s Razor):在多个可行模型中,选择最简单的能解释数据的模型
正则化
下面的 指的是权重向量,也就是 的系数。
- 正则化(Ridge / 岭回归)[4]
惩罚系数较大时,会导致参数更小更平滑,降低过拟合。
- 正则化(LASSO 回归)
范数更容易在坐标轴上取到,所以另外一个参数必须为 0,因此可以得到稀疏解,自然完成特征选择。
特征选择(Feature Selection)
选择重要特征,去掉冗余特征
LASSO 的稀疏解本质就是一种自动特征选择方法
逻辑回归
在线性回归中,目标变量 是连续的,而逻辑回归要解决 分类问题 (Classification):
- 输入:特征向量
- 输出:类别标签
可以分成软分类和硬分类:
- 硬分类:硬分类的输出是离散的类别标签,即模型会直接给出某个样本所属的类别。例如,对于一个二
分类问题,硬分类模型会输出“类别 A”或者“类别 B”。 - 软分类:输出是连续的概率值,即模型会输出每个样本属于各个类别的概率。
最常见的是:
- 二分类
例如:
- 1:垃圾邮件,0:正常邮件
- 1:肿瘤恶性,0:肿瘤良性
- 1:人脸匹配成功,0:不匹配
- 多分类
一般多分类可以拆成多个二分类(如 One-vs-All 方法)。
从线性回归到分类器
为什么直接用线性回归不行?线性回归输出的是实数:
但分类需要输出:
- 明确类别标签
或
- 属于某一类的概率(更好)
线性回归有两个问题:
输出不是概率(可能 <0 或 >1),例如预测癌症概率不能得到 1.3 或 -0.8。
使用单位阶跃函数不可导,若我们强行使用“硬分类”:
这是 不连续 的,无法用梯度优化。
Sigmoid 函数(Logistic 函数)
逻辑回归的核心思想:用线性函数得到一个值 ,再用 Sigmoid 将其变成一个概率。
Sigmoid 函数:
关键性质:
时 → 1
时 → 0
输出永远在 之间
可导:
这正适合做 概率模型。
逻辑回归的假设函数:
解释:
- 输出 = 输入属于正类()的概率
概率视角 的表达
对于二分类:
可写成统一形式:
如果:
- → 保留前项
- → 保留后项
这部分定义了模型的输出含义,也就是把问题名正言顺地变成了预测一个分类是 的概率。
Logit 几率比(odds ratio)
定义几率比:
例如:中彩票概率 0.1,则:
与逻辑回归的关系:
从模型:
推得:
再取对数(logit transform):
所以我们可以得到:对数几率是线性的,Sigmoid 函数是有用的,正确的。
意义:
逻辑回归实际上在学习:
特征如何影响 (几率比)
这是一种“线性解释的概率模型”。
用最大似然估计推导逻辑回归目标函数
逻辑回归的损失函数不像线性回归一样采用均方误差,而是用对数似然损失。这是因为 Sigmoid 下,均方误差是非凸函数,容易陷入局部最优,而对数似然是凸函数,好优化,可以用牛顿法。
“概率给事件,似然给参数”。这部分证明了下面的优化目标(对数损失)在数学上是唯一正确且最优。
逻辑回归模型的似然:
因为样本独立同分布(i.i.d.),取对数得到对数似然(便于推导):
这就是逻辑回归优化的目标函数。我们要求它的最大值。
使用梯度上升法优化参数
因为我们要最大化模型预测出正确标签的概率(上面得到的对数似然),所以用梯度上升:
梯度上升更新规则:
注意可与线性回归做对比:
- 线性回归是梯度下降()
- 逻辑回归是梯度上升()
推导梯度
与线性回归几乎一样。
因此有随机梯度上升(SGD)更新:
Softmax 回归(多分类)
Softmax 是 Sigmoid 函数在多分类上的推广。
当类别:
Softmax 回归模型输出 个概率,它们的总和为 :
组合写法:
Softmax 是逻辑回归的多分类扩展:Sigmoid 是二分类概率归一化,Softmax 是 类概率归一化。
补充:Softmax 的目标函数是交叉熵,后面神经网络还会讲。
牛顿法(Newton Iteration)
牛顿法的本质是利用一阶与二阶导数,通过“局部二次近似”求方程的根,例如求方程 的牛顿公式,目标求解:
牛顿迭代公式:
也就是把 用泰勒展开近似成直线,然后找它的根。那我们要求 的极大值点,就是相当于把 替换成 的导函数 :
Newton–Raphson 方法
但是机器学习中,要求的参数是一个向量,而不是一个常数,所以需要进行处理:
- 一阶导 转换成梯度向量
- 二阶导 转换成 Hessian 矩阵 ,取反了就是逆矩阵
更新公式得到:
如果把 Hessian 矩阵换成 Fisher 信息矩阵 ,它是 Hessian 矩阵的期望的取反,就得到了 Newton-Raphson 方法的变体 Fisher Scoring。
在逻辑回归中,计算期望往往比直接计算 Hessian 矩阵更方便,且性质更好(半正定)。它能比梯度上升收敛得更快。
这部分应该只考公式默写和思路简述,手搓牛顿法梯度下降这种计算机干的事情还是有点太非人类了。
牛顿法和梯度下降法
现在的深度学习一般都不用牛顿法,因为计算量太大了。
| 梯度下降 | 牛顿法 | |
|---|---|---|
| 利用信息 | 一阶导数,只知道坡度 | 一阶+二阶导数,知道坡度和曲率 |
| 几何直观 | 盲人下山,一步步试探 | 用二次曲面拟合,直接跳到坑底 |
| 收敛速度 | 慢,线性收敛,迭代次数多 | 快,二阶收敛,通常几次迭代即收敛 |
| 单步计算量 | 小,只算梯度 | 极大,需计算 ,复杂度 |
| 适用场景 | 特征维度 很大 ,如深度学习 | 特征维度 较小,如传统统计模型 |
| 超参数 | 需要手动调学习率 | 无需学习率,步长自然确定 |
模型评估方法与性能评价指标
逻辑回归属于分类模型,因此我们需要:
- 避免过拟合/欠拟合
- 正确划分数据集
- 正确评价模型性能
过拟合与欠拟合
过拟合:模型过度学习训练集的细节和噪声会导致测试集表现变差。
原因包括:
- 模型太复杂
- 特征太多
- 数据量太少
- 参数权重太大
解决:
- 正则化(/)
- 更多样本
- 降低特征维度
数据集划分
| 数据集 | 作用 | 比例 |
|---|---|---|
| 训练集 | 拟合模型 | 50%~80% |
| 验证集 | 调超参数 | 10%~20% |
| 测试集 | 最终评估,不能再调参 | 10%~30% |
常见划分方法:
留出法(Hold-out):一次性划分 训练 / 验证 / 测试。
- 缺点:容易受切分的随机性影响。
交叉验证(Cross-validation):将数据切成 折:
每次选择 折做验证
其他 折做训练
轮结果平均
最常用:
当 (样本数)时就是留一法 LOOCV
自助法 Bootstrapping(有放回抽样):每次抽样 次(有放回),约有 样本落入测试集。
优点有:
小数据集非常有用
Bagging 等集成学习强依赖该方法
分类性能指标
分类评价不仅仅是准确率。
混淆矩阵(Confusion Matrix)
| 预测正类 | 预测负类 | |
|---|---|---|
| 真实正类 | TP | FN |
| 真实负类 | FP | TN |
这是后面所有指标的基础。
准确率 Accuracy
适用于数据平衡的场景。
精确率 Precision(查准率)
预测为正的样本中,有多少是真正的正例。
用于:垃圾邮件、广告点击预测等 假正成本高 的任务。
召回率 Recall(查全率)
真实为正的样本中,有多少被找出来。
用于:疾病预测、地震预测、作弊检测等 漏报代价高 的任务。
F1 分数(调和平均)
当需要均衡 Precision 和 Recall 时使用。
平均每类准确率(Average Per-class Accuracy)
用于多分类:
比总体 Accuracy 更能体现多类任务中的表现。
ROC 曲线
横轴:FPR(假正例率)
纵轴:TPR(真正例率)= Recall
每个阈值对应一个 (FPR, TPR) 点,连接形成 ROC 曲线。
AUC
就是 ROC 曲线下的面积
- AUC = 1 → 完美分类器
- AUC = 0.5 → 随机猜测
- 越大越好
特点:
- 不受类别不平衡影响(非常重要)
- 光滑 ROC 曲线表明模型未过拟合
支持向量机(SVM)
SVM 是一种二类分类模型。 它的基本模型是定义在特征空间上的间隔最大的线性分类器, 间隔最大使它有别于感知机。
SVM 的学习策略是间隔最大化,可以形式化为一个求解凸二次规划的问题,也等价于正则化 Hinge 损失函数的最小化问题。SVM 的学习算法通过求解凸二次规划的最优化算法来实现。主要有三种 SVM:
线性可分支持向量机(Linear Support Vector Machine in Linearly Separable Case):
- 硬间隔最大化(Hard Margin Maximization)
线性支持向量机(Linear Support Vector Machine)
- 训练数据近似线性可分时,通过软间隔最大化(Soft Margin Maximization)
非线性支持向量机(Non-linear Support Vector Machine)
- 当训练数据线性不可分时,通过使用核技巧(Kernel Trick)及软间隔最大化
关于核函数和核技巧:
- 当输入空间为欧氏空间或离散集合、特征空间为希尔伯特空间时,核函数(Kernel Function)表示将输入从输入空间映射到特征空间得到的特征向量之间的内积。
- 通过使用核函数可以学习非线性支持向量机,等价于隐式地在高维特征空间中学习线性支持向量机,这样的方法称为核技巧。
- 核方法(Kernel Method)是比支持向量机更为一般的机器学习方法。
在 SVM 之前,感知机[3]和神经网络已经存在了。但是它们有一个大问题:小样本下的过拟合,也就是**“过学习”与“泛化能力”的矛盾**。
小样本(Small Sample)是指在统计学和机器学习中,可用于训练模型的数据点数量相对较少的情况。在这种情况下,样本的数量不足以全面代表整个数据的分布特性。小样本学习是统计学习理论中的一个重要概念,它关注的是如何在样本数量有限的情况下构建有效的学习模型。小样本的特点:
- 数据稀缺:可用的数据量有限,可能不足以覆盖所有可能的情况或特征。
- 泛化风险:由于样本数量少,模型可能无法很好地泛化到新的、未见过的数据上。
- 过拟合倾向:模型可能会过度拟合训练数据中的噪声和细节,导致在新数据上的预测性能下降。
- 统计推断困难:在小样本情况下,对数据的统计推断可能不够准确或可靠。
那么,SVM 就要在传统的小样本问题上进行改进:
经验风险最小化 (ERM):
- 传统的统计学(如大数定律)通常假设样本量无穷大,但在现实应用中,数据往往是有限的(小样本)
- 在样本很少的情况下,如果非要强求模型在训练集上表现完美(经验风险最小化,ERM),模型就会变得非常复杂,像是在“死记硬背”训练数据,连噪声都记住了,这也就容易导致过拟合
结构风险最小化 (SRM):我们要找一个模型,它不仅要**“分得对”(训练误差小),还要“长得简单”(模型复杂度低)。于是 SVM 基于统计学习理论**,采用 SRM 策略,解决这两个矛盾。
SVM 的目标是控制期望风险的上限,核心公式:
- 左边:我们真正关心的未来表现
- 期望风险 :模型在未知测试数据上的真实误差
- 右边:要优化的目标(结构风险 )
- 第一项 :经验风险。即模型在训练集上的平均损失(分错了多少)
- 第二项 :置信范围(模型复杂度惩罚)。它与样本数 成反比,与 VC 维 (模型的复杂程度,SVM 通过最大化几何间隔来实现)成正比
- 左边:我们真正关心的未来表现
含义: SVM 不只看训练误差(经验风险),还强行限制模型的复杂度(置信范围)。它试图在“分对数据”和“模型简单”之间找平衡
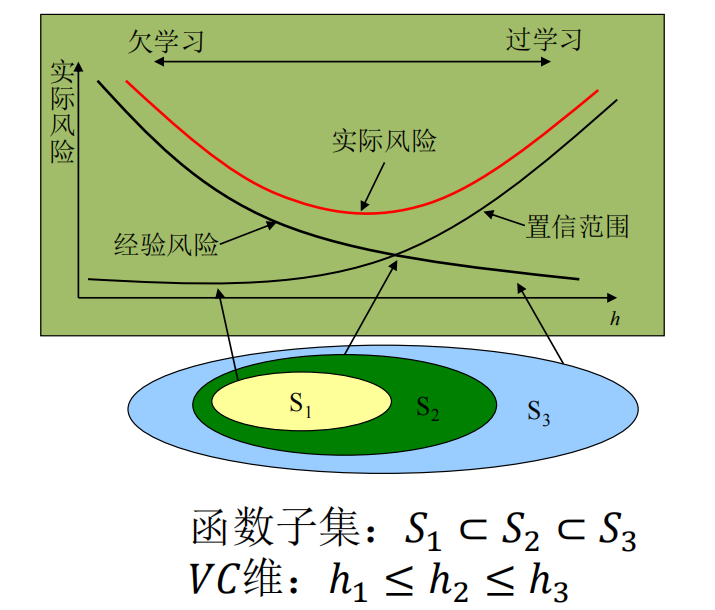
这就是 SVM 为什么要搞“最大间隔”的理论依据。
- 最大间隔 本质上就是在限制模型的复杂度(降低 VC 维)。
- 直观上:间隔越大,对噪声的容忍度越高,鲁棒性越强。
- 因为限制了复杂度,所以哪怕样本不多,SVM 也能保证很好的推广能力(泛化能力),不容易过拟合。
本章背诵公式整理
硬间隔原始问题及约束
拉格朗日对偶问题的目标函数和约束
软间隔 SVM 的问题及约束
高斯核函数
SVM 的决策函数
什么是“最好的分类”?
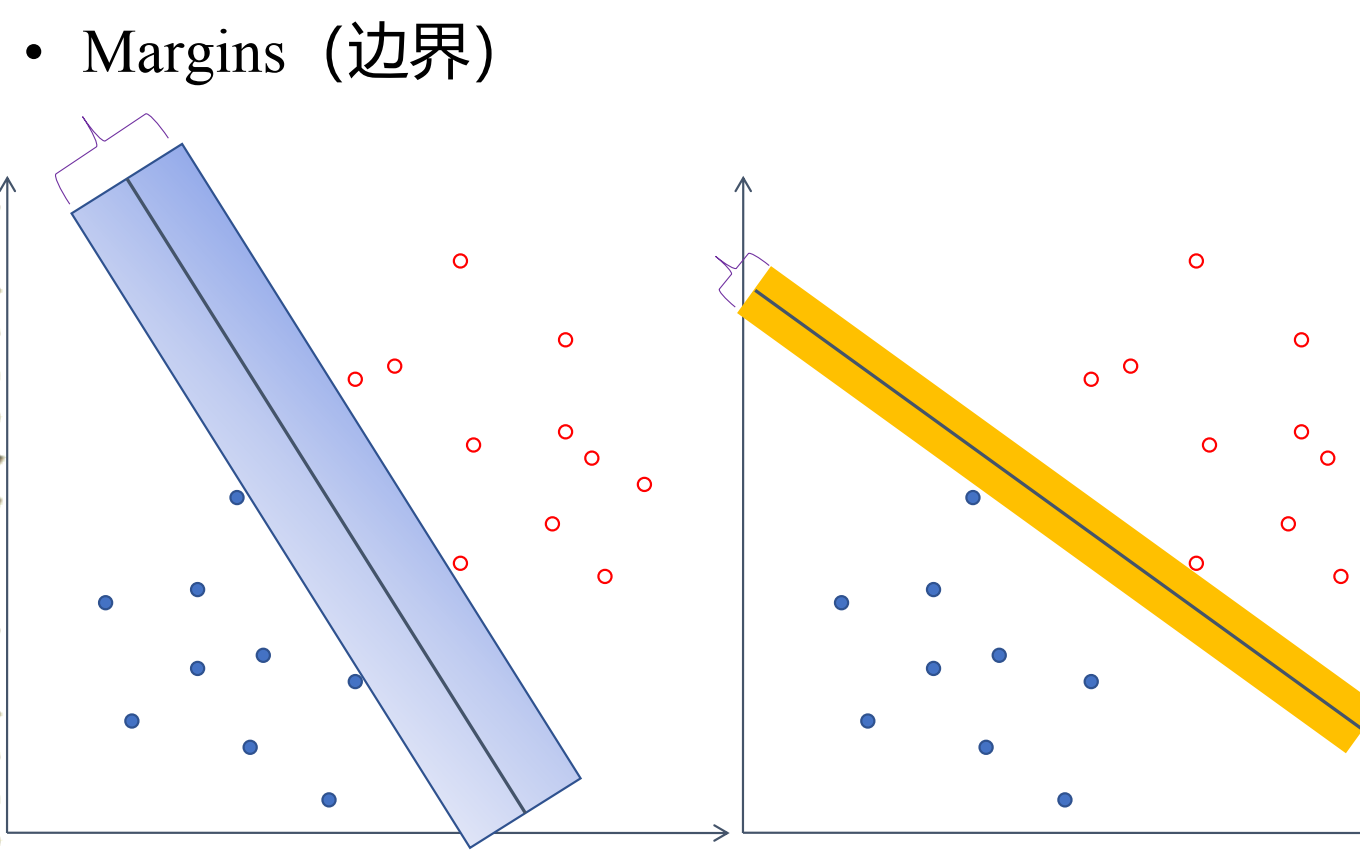
假设桌子上有一堆红球和蓝球(线性可分),你可以用无数根棍子(超平面)把它们分开。哪根棍子最好?
- 感知机:只要分开就行,不管棍子是不是贴着球。这种的解有无穷个。
- SVM:这根棍子不仅要分开球,还要离两边的球都尽可能远。
- 间隔 (Margin):棍子到最近的球的距离。
- 目标:找到最大化间隔 (Max Margin) 的那个超平面。
硬间隔线性可分 SVM
这是 SVM 的“理想形态”,线性可分的意思就是:数据是完美的,完全可以用一条直线分开。
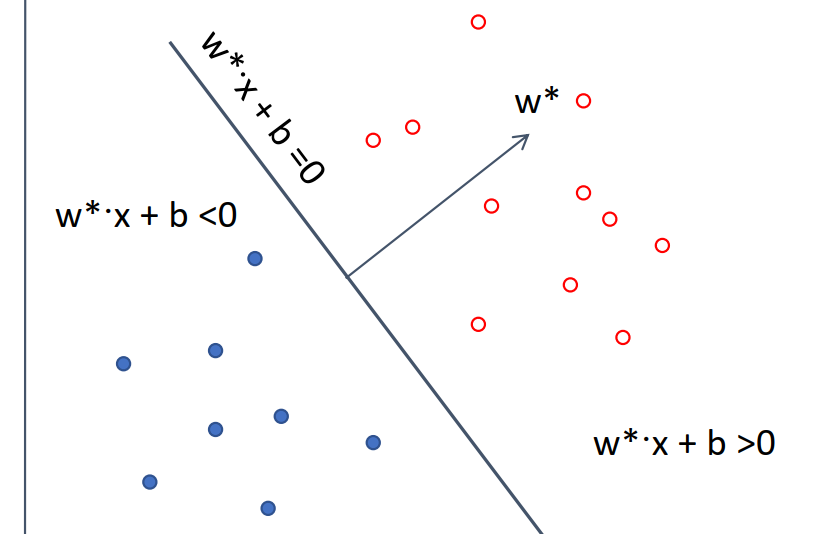
超平面与决策函数
- 超平面方程:
- :法向量,决定平面的方向。
- :截距,决定平面的位置。
- 决策函数:
- 结果为 +1 是正类,-1 是负类。
支持向量
支持向量指的是在所有样本点中,离超平面[5]最近的那些点。
也就是所有满足 的点。
- 作用:它们“支撑”起了分类边界。SVM的独特之处在于,决定这条分界线的,只有这些少数的支持向量,其他离得远的点删掉也不影响结果(这与逻辑回归不同,逻辑回归所有点都起作用)。
间隔
假设空间中的训练数据集:
点到平面的距离公式:。 被称为几何间隔。
约束条件:要求所有点都被正确分类,且都在间隔之外。
- 左边的项被称为函数间隔。
- 其实右边可以是任何常数 。为了数学方便,我们通过缩放 和 ,强制让最近点的函数间隔 。这叫规范化。
几何间隔:对于支持向量,距离就是 ,因为 ,所以 。
总间隔:正负两类支持向量之间的距离是 。
最终优化目标(Primal Problem 原始问题)
我们要让间隔 最大,等价于让分母 最小,为了方便求导,改为最小化 。
这是一个凸二次规划问题(Convex Quadratic Programming)。
通过间隔最大化或等价方法求解相应的凸二次规划问题学习得到的分离超平面为:
决策函数是:
例题
也可以用支持向量的几何特征来算, 和 肯定是支持向量,代入进方程是 1,它们的连线也是垂直于超平面的,可以这样算出来。

拉格朗日优化算法
这一部分是数学推导的核心。直接解带约束的原始问题很难。我们通过拉格朗日乘子法,把约束条件“融合”到目标函数里,变成一个新问题(对偶问题)。好处在于:
对偶问题更容易求解。
将原始问题中的不等式约束转为了对偶问题中的等式约束。
对偶问题自然引入了内积形式,可以引入核函数轻松计算。
我们求解问题的步骤是:
- 利用拉格朗日乘子法,构造拉格朗日函数;
- 利用强对偶性(KKT 条件)将优化问题进行转化,并求解;
- 利用最优的 和 构建分类器。
拉格朗日函数
拉格朗日方法的本质不需要深究。简单地说它就是把约束变成了惩罚,如果不满足约束,拉格朗日函数 后面那一项就会特别大,迫使优化过程回到可行域。[6]
拉格朗日函数的形式:
- 原始问题的优化目标: (极小极大问题)
- 对偶问题的优化目标: (极大极小问题)
强对偶性:当满足某些条件(KKT 条件)时,这两个问题的解是一样的。我们选择解对偶问题。
求解
- 求极小:让 对 和 求偏导为 0。
- 得出的关系式: (权值向量 是样本向量的线性组合)。
- 以及约束:。
代回 :把上面的关系代回 ,消去 和 。得到只包含 的目标函数:
求最大则等价于求:
求解:假设最优解是 。则存在任意一个 使得 ,并可以得到解[7]:
决策函数
如果是用的核函数,就把 换成 即可
例题

KKT 条件
KKT 条件是强对偶成立,可以允许用拉格朗日方法求解的必要条件,其中最重要的是互补松弛条件:
含义:
- 如果 ,则后面括号必须为 0,那么样本在边界上,是支持向量。
- 如果后面括号 (样本在边界外),则 必须为 0,不是支持向量。
- 这证明了只有支持向量决定模型参数。
SMO 算法
求解 还是很难,变量太多。所以可以用 SMO 算法来解那个全是 的方程。
SMO 的思路:每次只挑两个变量 来更新,固定其他变量。这样就把复杂问题变成了简单的二次函数求极值问题(有解析解)。解析解快,收敛也快。
SVM 的优缺点
优点:
- 泛化错误率低
- 计算开销不大(取决于支持向量数量)
- 结果易解释(支持向量)
- 适合小样本
缺点:
- 对参数(如 和核参数)敏感
- 对缺失数据敏感
- 大规模数据训练慢
线性支持向量机的软间隔
现实数据往往有噪声(比如红球堆里混进了一个蓝球),硬间隔会导致无解或过拟合。所以我们可以通过引入松弛变量允许少量误分,换取更大的间隔。于是我们引入松弛变量 (Slack Variable) 。
- 允许样本点不满足约束条件,“犯错”,跑进间隔里,甚至跑到对面去。
- 约束变为: ()。
新的目标函数:
- (惩罚参数):
- 很大,就意味着对错误零容忍,让点逼近硬间隔(易过拟合)。
- 很小,就意味着容忍更多错误,让间隔更宽(易欠拟合)。
- Hinge Loss:这一项实际上等价于合页损失函数 。
软间隔的对偶问题
形式和硬间隔几乎一样,唯一的区别是 的约束变了:
非线性 SVM 和核方法(Kernel Trick)
这是 SVM 最天才的地方,怎么解决线性不可分(如XOR问题)?就可以用到核方法把数据映射到高维去,建立非线性的 SVM,然后用核函数计算避免高维计算灾难。
升维
世界真奇妙。
- “低维空间不可分,映射到高维空间就线性可分了。”
- 映射函数 :把 变成高维向量。
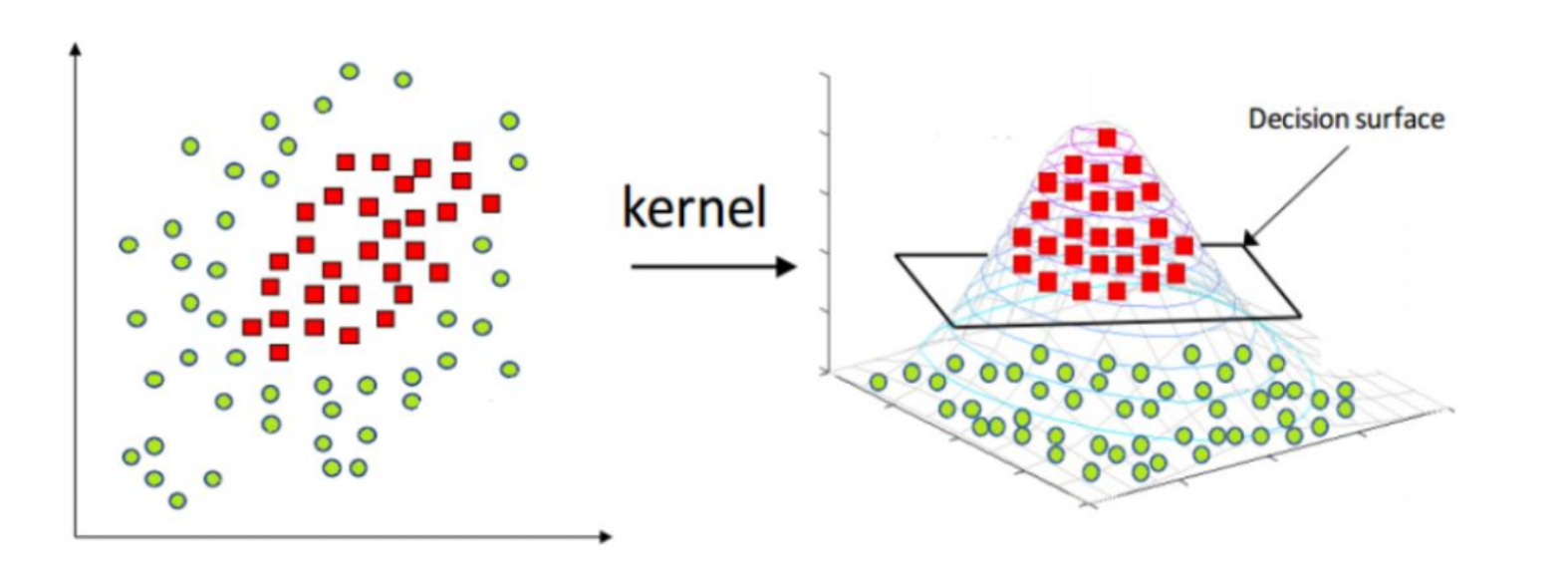
维数灾难与核方法
问题:变成高维向量后,高维空间(甚至无穷维)计算内积 计算量太大,算不动。
核函数 的定义:存在一个函数 ,算它等于直接在高维空间算内积(这是一个发现)。
好处:我们不需要知道 具体长什么样,也不用去高维空间死算,直接在低维空间套用 公式就行。
常见的核函数
- 线性核: (就是原始 SVM)
- 多项式核:
- S 形核(双曲正切核):
- 高斯核(RBF):
- 特点:映射到无穷维空间。
- 参数 : 越小,高斯分布越尖,模型越复杂(易过拟合); 越大,越平滑(易欠拟合)。
SVM 回归 (SVR)
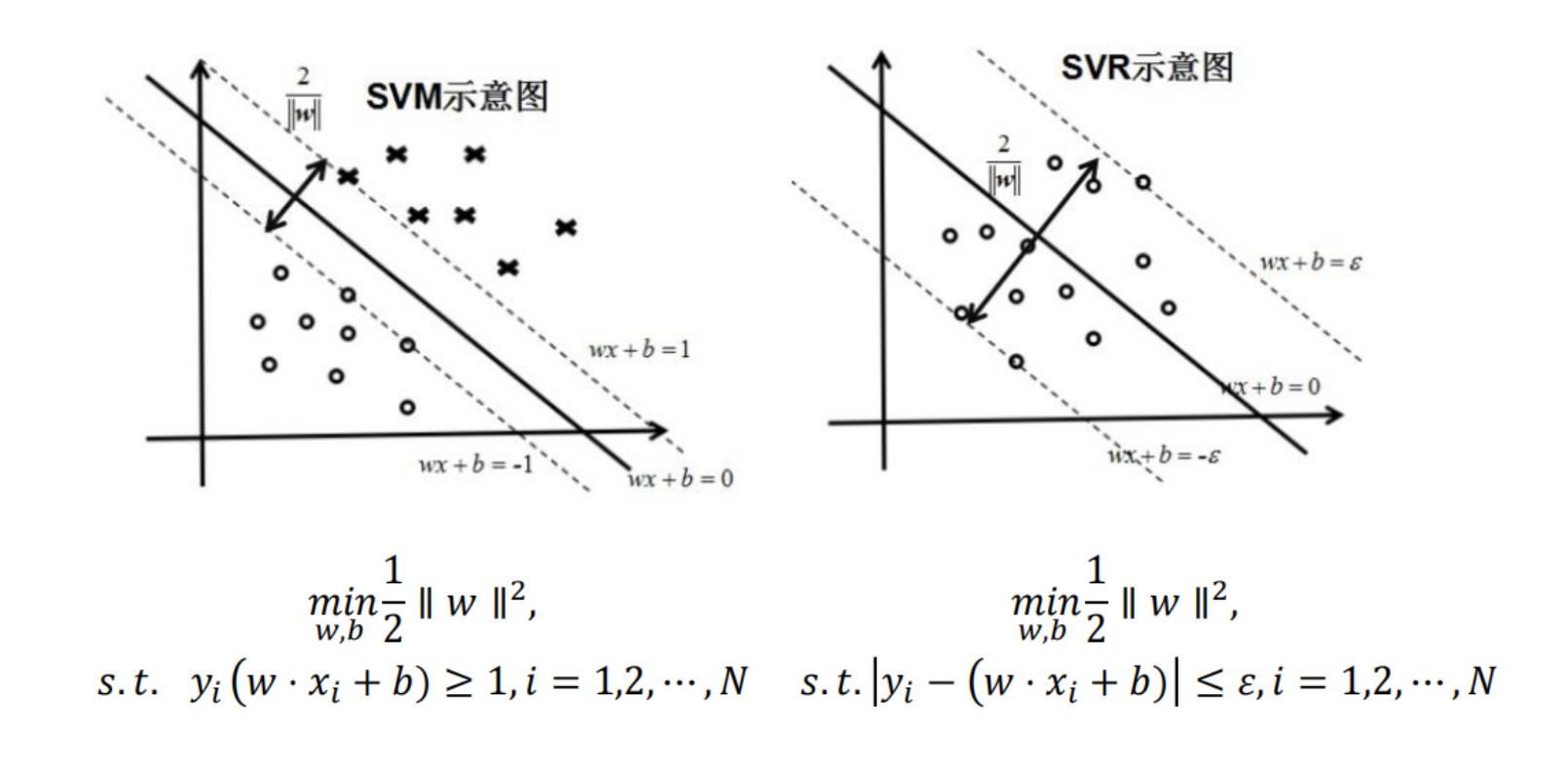
SVM 也可以做回归预测。核心区别:
- SVM 分类:追求间隔最大,希望点都在间隔带之外。
- SVR 回归:追求点都在间隔带之内。我们容忍 范围内的误差。
SVR 同样也可以加入松弛因子 。
-不敏感损失函数
- 只要预测值 和真实值 的差值小于 ,损失就为 0(认为是预测对了)。
- 只有差值超过 ,才计算损失。
- 几何意义:这就相当于构建了一个宽为 的“管道”,在这个管道里的点我们都不管,只优化管道外的点。
有了管道,我们也可以得到 SVR 间隔带的宽度是:
因为管道的宽度 是一个常数,所以我们要想让宽度最大[8],也就是要让 最小,和 SVM 是殊途同归的。
降维
随着特征维度增加,数据在空间中变得极其稀疏,计算量呈指数级增长,且距离度量(如欧氏距离)逐渐失效,这就导致了维数灾难(Curse of Dimensionality)。所以我们需要降维。
降维(Dimensionality Reduction)是将训练数据中的样本(实例)从高维空间转换到低维空间。该过程与信息论中有损压缩概念相似,完全无损的降维是不存在的。
降维方法又分为线性降维和非线性降维,非线性降维又分为基于核函数和基于流形等方法。
降维的目的是:
- 降低计算复杂性: 简化数据分析和建模的过程,使得模型训练和预测更高效。
- 提高可视化效果: 降维后的数据更易于进行可视化,从而帮助理解数据的结构和模式。
- 减少冗余信息: 通过压缩数据,去除多余的噪声和不相关的信息,使得数据更简洁和有意义。
其中有两种特殊情况:
- 将一个高维变量系统有效的降至二维
- 高维不可见空间(抽象思维)变成直观平面图示(形象思维)。
- 增加决策知识,提高决策人员的洞察能力。
- 这种方法的目的是将高维数据投影到二维空间,使得数据能够以平面图示的方式直观展示。这种转换可以帮助决策者更清晰地理解复杂数据的结构和模式,从而增加决策知识,提高洞察能力。
- 应用例子: 假设你有一个包含很多变量的数据集,通过降维,你可以将这些数据转换成一个二维的散点图。这种图表能够帮助决策者识别出数据中的关键趋势和群组,进而做出更明智的决策。
- 将一个高维变量系统有效的降至一维
- 将高维指标系统变成综合指数。
- 这种方法将高维数据简化为一个综合指数,便于对整体趋势进行评估和比较。例如,将多个经济指标综合成一个代表经济健康程度的指数。
降维不是将多余的维度直接删除,而是将特定的维度进行融合。于是维度就从原先的物理测量,变成了抽象的概念值。消除“相关性”,提取“主要矛盾”。
相关性和冗余:“身高”和“腿长”通常是高度正相关的(高个子通常腿长)。
数学视角:这两个维度提供了重复的信息。在几何上,数据点并没有布满整个二维平面,而是挤在一条斜线附近。
降维操作:既然它们挤在一条线上,我为什么还要用两个坐标轴 去描述它?我直接沿着那条线的方向建立一个新的数轴,只用一个坐标就能描述大部分信息了。这就是把 2 维降到了 1 维。
信号和噪声
数学视角:数据中变化剧烈(方差大)的方向通常代表了信号(Signal),而变化微小(方差小)的方向通常代表了噪声(Noise)。
降维操作:保留方差大的方向,丢弃方差小的方向。
主成分分析(PCA)
PCA 是无监督、线性的降维方法,通过平移、旋转坐标轴(基变换)完成对数据原始特征空间的重构。
想象一个椭圆状的饼,只用一条线来描述它,怎么画?
- 方向一:沿着饼最长的方向画(方差最大,信息保留最多)。
- 方向二:与方向一垂直(正交,互不相关)。
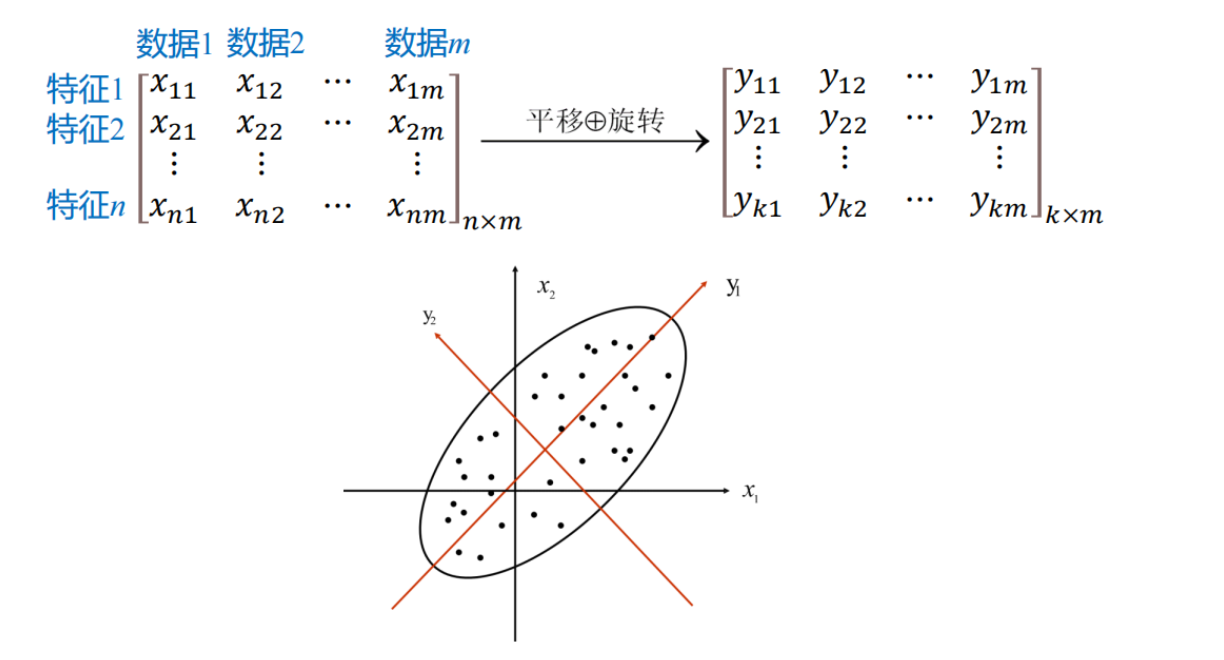
PCA的两个核心目标(数学本质):
- 最大方差理论:降维后的数据在新的坐标轴上分布得越散越好(方差大 = 信息量大)。
- 最小重构误差:降维后能尽可能恢复回原来的数据。
(注:这两个目标在数学上是等价的)
PCA 的数学逻辑
符号列表:
- :数据矩阵
- 一般是 的矩阵
- 每行是一个样本
- 每列是一个特征
- 注:PPT 上面是反过来的
千万要注意数据是一行还是一列!
- :协方差矩阵,描述特征之间的相关性
- ,是一个 方阵
- 对角线元素表示各个特征的方差
- 非对角线元素表示特征之间的协方差(对称的)
- 如果是每列是一个样本,那就是
- :特征值,表示主成分的方差
- 越大则对应特征向量的方向越重要
- 使用 求解
- 是单位矩阵
- 是特征向量,就是新的主轴
- 将 回代进 求 ,一般需要再将它归一化
- :变换矩阵,由选出的特征向量组成的矩阵
- :降维后的矩阵
- 其中的新样本 就是主成分,第一主成分就是影响最大的主成分,以此类推
协方差 (Covariance):衡量两个特征的相关性。
- 表示两个特征线性无关(正交)。
- 我们希望降维后的特征之间互不相关,即协方差为 0。
协方差矩阵 (Covariance Matrix):
- 对角线:是各个特征的方差(我们要最大化它)
- 非对角线:是特征间的协方差(我们要让它变为 0)
- 理论上这里除以 和 ,或者不除以 都没影响,得到的答案是一样的
对角化:
- 我们的目标就是找一个变换矩阵 ,使得变换后的协方差矩阵 是一个对角矩阵
- 线性代数知识:实对称矩阵(协方差矩阵就是)可以通过特征值分解来对角化
- 结论:变换矩阵 的每一行,就是协方差矩阵 的特征向量
PCA 算法的步骤
算法流程:
- 中心化 (Centering):所有的样本减去均值(保证均值为 0)。
- 计算协方差矩阵:。
- 特征值分解:求 的特征值 和特征向量 。
- 排序与筛选:将特征值从大到小排序,选前 个对应的特征向量。
- 投影: ( 是选出的特征向量组成的矩阵)。

PPT 例题
假设数据矩阵 (已经过去均值):
这里 (2维特征), (5个样本)。
Step 1: 计算协方差矩阵
算出结果(PPT P21):
(注:PPT里用的系数好像是1/5而不是1/4,考试时请注意题目要求是用 1/m 还是 1/(m-1),通常数据量大时差别不大,统计学上样本方差用m-1)
Step 2: 求特征值
解方程 :
解得:。
Step 3: 求特征向量
- 对于 ,代入 ,解得特征向量 。
- 注意:特征向量通常需要单位化(归一化)!
- 单位化后:。
- 对于 ,同理解得 。
Step 4: 降维
如果要降到 1 维,选最大的特征值 对应的向量 。
变换矩阵 。
降维后的数据 。
容易混淆的概念(LMS vs PCA)
- 我们在讲线性回归时提到了 LMS (最小均方)。
- 注意:PCA 最小化的是重构误差(点到直线的垂直距离),而线性回归最小化的是预测误差(点到直线的竖直距离)。两者几何意义不同,不要混淆。
主成分的统计特征
主成分的均值为 0
- 因为原始数据已经中心化了,所以线性组合以后的主成分 的均值也是 0。
主成分的方差为
不同主成分之间互不相关,协方差为 0
- 这就意味着 PCA 消灭了特征之间的冗余
- 这就意味着 PCA 消灭了特征之间的冗余
异常点检测和辅助分析
累计贡献率:用来决定保留多少个维度 ()。
公式:
通常要求累积贡献率达到 85% 或 95% 以上。
判断“异常点”:如果一个样本点在某个很次要的主成分( 很小)上有很大的投影值,说明它违背了数据的主要分布规律。
- 度量指标:如果 的值很大,说明样本 在第 主成分上异常。
数据重构:降维是不可逆的(信息丢失),但我们可以近似恢复原始数据。
- 公式:
- 矩阵形式: (其中 是特征向量矩阵, 是降维后的数据)
- 如果之前减去了均值,记得加回去
- 如果 (保留所有特征),则数据可以完全重构(无损);如果 ,则会有重构误差。
PCA 与 神经网络
这部分联系了生物学和数学。
Hebb 学习规则:
- 生物学假设:“Together fired, together wired”(同时兴奋的神经元连接会增强)。
- 公式: (权重增量 = 输入 输出)。
- 问题:权重 会无限增长,发散。
Oja 学习规则:
- 这是 Hebb 规则的改进版,引入了归一化/遗忘因子,防止权重无限增长。
- 结论:使用 Oja 规则训练的单个神经元,其权重向量 最终会收敛到输入数据协方差矩阵的第一主成分(最大特征向量)。
- 意义:证明了神经网络可以通过无监督学习自动提取主成分。
PCA 算法的优缺点
优点
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素
- 计算方法简单,主要运算时特征值分解,易于实现
- 它是无监督学习,完全无参数限制的
缺点
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响
表征学习与自编码器 (AutoEncoder)
这是深度学习时代的降维方法,主要在 PPT 后半部分,通常考选择或简答。
表征学习 (Representation Learning)
- 概念:让机器自动学习特征,而不是人工设计特征。
- 分类:
- 监督(如 CNN 分类)
- 无监督
- 自监督(如自编码器)
自编码器 (AutoEncoder, AE)
结构:
- 编码器 (Encoder):压缩数据,(降维)。
- 解码器 (Decoder):还原数据,。
原理:训练网络让输出 尽可能接近输入 ()。
中间层 (Bottleneck):中间那层神经元很少,迫使网络学会数据的“精华”表示。这本质上就是一种非线性的PCA。
变体
- 去噪自编码器 (Denoising AE):输入加噪声,强制网络学会还原干净数据,鲁棒性更强。
- 卷积自编码器:用于图像。
聚类
聚类是一种是最常见的无监督学习算法,指的是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。
主要的聚类算法分成:
- 划分聚类(K-means、 K-medoids等):给定包含 个点的数据集, 划分法将构造 个分组, 每个分组代表一个聚类, 这里每个分组至少包含一个数据点, 每个数据点属于且仅属于一个分组。
- 层次聚类(凝聚法、分裂法):将给定数据集进行逐层分解,直到满足某种条件为止。有自顶向下和自底向上两种。
- 密度聚类(DBScan、 基于密度峰值算法):不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现“球形”聚簇的缺点。只要一个区域中点的密度大于某个阈值,就把它加到与之相近的聚类中去。
- 网格法(STING、 CLIQUE):将数据空间划分成有限个单元的网格结构,所有的处理都是以单个的单元为对象。
- 模型法:给每一个聚类假定一个模型,然后去寻找能很好的拟合模型的数据集。
- 概率模型:高斯混合模型(Gaussian Mixture Models)
- 神经网络模型:SOM 模型
- 吸引子传播算法:AP 聚类
- 谱聚类
要聚类,先得知道两个点像不像(距离远近),所以需要距离度量:
闵可夫斯基距离 (Minkowski Distance):
- :欧氏距离(最常用,两点间直线)。
- :曼哈顿距离(走街区直角)。
余弦相似度 (Cosine Similarity):
- 衡量两个向量方向是否一致,常用于文本分类。
- 计算公式:。
划分聚类和 K-Means 算法
K-means 聚类,也称为 K-平均或 K-均值聚类,因为要涉及到算均值,所以名字带 means。
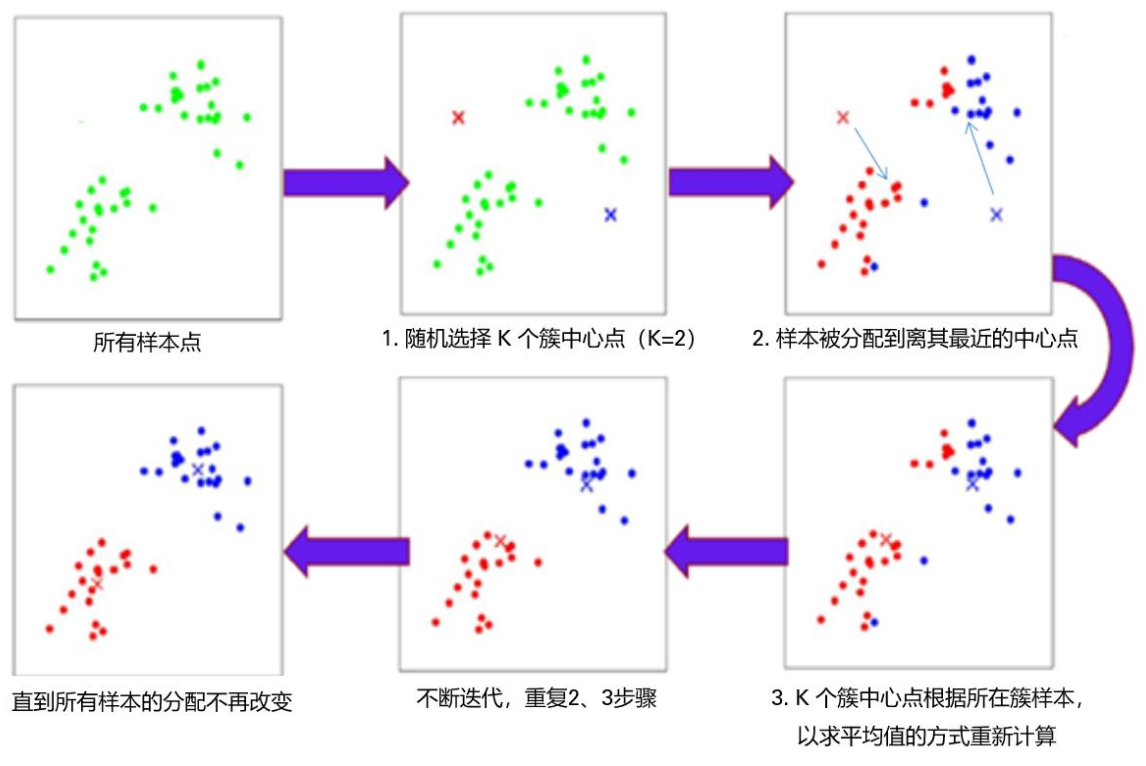
K-Means 算法的流程如下:
- 初始化:随机选 个点作为初始质心(Centroids)。
- 分配 (Assignment):计算每个样本到这 个质心的距离,把它归到最近的那个质心所在的簇。
- 更新 (Update):重新计算每个簇的均值(Mean)[9],作为新的质心。
- 迭代:重复 2 和 3,直到质心不再变化或达到最大迭代次数。
例题

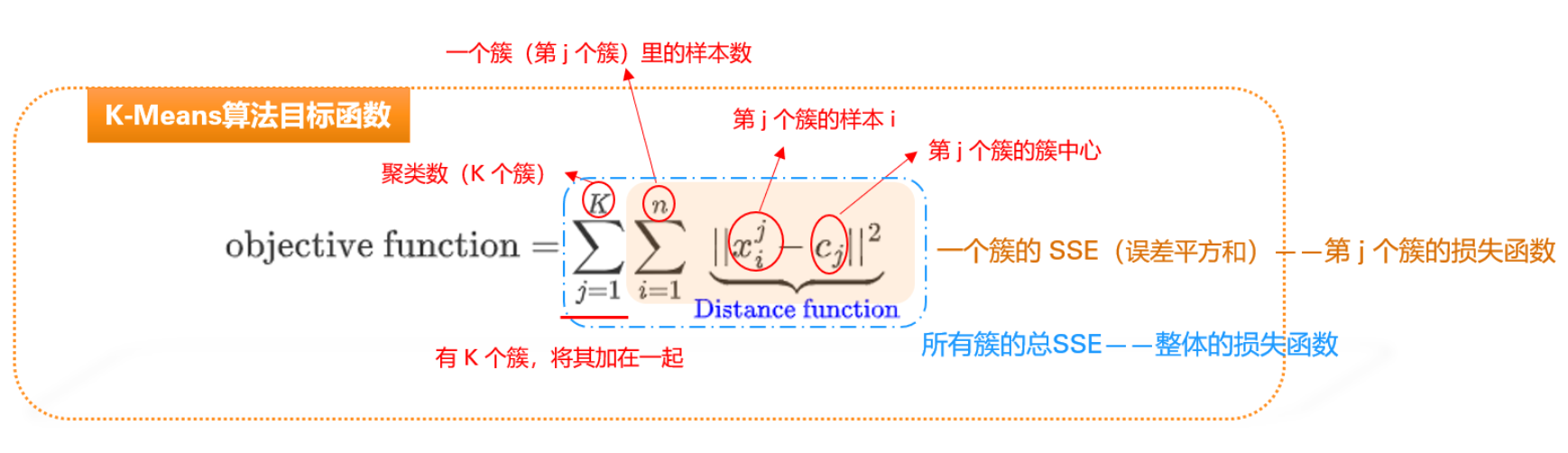
K-means 的损失函数
K 值的选择
一般使用肘部法:画出 值与损失函数(SSE,误差平方和)的关系图。在曲线弯曲像“手肘”的地方,就是最佳的 。
K-means 方法的优缺点
优点:
- 简单,快速
- 可解释性强
- 簇是密集的,效果好
缺点:
- 需预设
- 对初值敏感:初始点选不好,结果可能很差(容易陷入局部最优)
- 对噪声/离群点敏感:一个离得特远的点会把均值拉偏
- 只能聚凸形簇:对于环形、月牙形数据无能为力
- 只适合数值型数据的聚类
K-Medoids 算法(中心点算法)
是 K-means 的改进版。
- 区别:不用“均值”做质心,而是选簇里实际存在的某个点(中位数点)做质心。
- 好处:对噪声(离群点)不敏感(鲁棒性强)。
层次聚类 (Hierarchical Clustering)
不需要预设 值,能生成一棵树状图 (Dendrogram)。
主要有两种策略:
- 凝聚法 (Agglomerative):自底向上。开始时每个点都是一个簇,然后两两合并,直到剩下一个大簇。
- 分裂法 (Divisive):自顶向下。

簇间距离
要把两个簇合并,怎么算它们之间的距离?
- Single Linkage (最小距离):两个簇中最近两点的距离。
- 特点:容易产生“长链”效应。
- Complete Linkage (最大距离):两个簇中最远两点的距离。
- 特点:倾向于球形簇。
- Average Linkage (平均距离):所有点对距离的平均。
- Ward Linkage:合并后导致方差(SSE)增加最小的两个簇。
层次聚类的特点
- 无需事先指定类的数目
- 需要确定相异度和联接度量准则
- 运算量较大,适用于不太大规模的数据
- 一旦一个步骤(合并或分裂)完成,就不能撤销或修正,因此产生了改进的层次聚类方法,例如BRICH, BURE, ROCK, Chameleon 等
密度聚类
解决 K-Means 无法聚类非球形数据(如笑脸图)的问题。它将簇定义为密度相连的点的最大集合,能够把具有高密度的区域划分为簇。
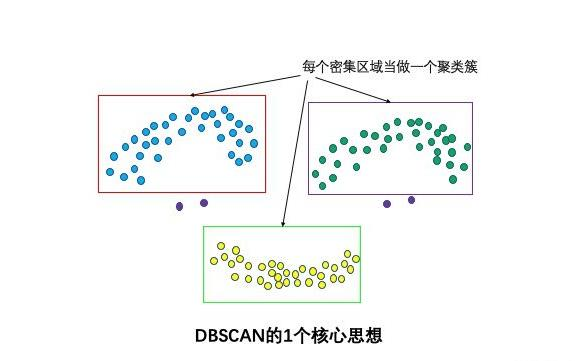
核心概念:
- 邻域半径 和邻域
- 核心对象:给定一个数目 , 如果对象的 领域内,至少含有 个对象, 该对象就是核心对象
- 当邻域半径 内的点的个数大于 时, 就是密集点
三种点的角色:
- 核心点:半径 内的邻居数
- 边界点:在核心点的邻域内,但自己不是核心点
- 噪声点:既不是核心点,也不是边界点
聚类逻辑
- 密度直达/可达/相连:只要两个核心点离得近,它们所在的簇就合并。
- 优点:不需要设 ,能发现任意形状的簇,抗噪声。
- 缺点:参数 和 难调,高维数据效果差。
基于模型与网格的聚类
- GMM(高斯混合模型):
- 认为数据是由 个高斯分布混合生成的。
- 属于软聚类(Soft Clustering),输出的是属于某类的概率。
- 求解使用 EM 算法(E 步猜类别概率,M 步更新高斯参数)。
- 网格聚类 (Grid-based):
- 把空间划成网格,只处理网格单元。速度快,但精度低。
聚类性能度量
外部指标
假设我们知道真实的类别标签(比如测试集)。
- Jaccard 系数 (JC)
- Rand 指数 (RI)
- 核心逻辑:看聚类结果里“被分到同一组的一对样本”在真实标签里是不是也是同一组。
内部指标
更常用的指标。只有数据,没有标签。目标:簇内越紧密越好,簇间越疏远越好。
- DBI (Davies-Bouldin Index):
- 计算(簇内平均距离之和 / 簇中心距离)。
- 越小越好。
- Dunn Index (DI):
- 计算(簇间最短距离 / 簇内最大直径)。
- 越大越好。
- (记忆技巧:Dunn 希望分子大分母小,所以越大越好;DBI 反之)
SOM 和 AP 聚类
SOM(自组织映射网络)
- 本质:一种无监督神经网络,用于聚类和降维。
- 核心机制:竞争学习(胜者为王)。输入一个样本,所有神经元比赛谁离它近。最近的那个(Winner)带着它的邻居们一起更新权重,向样本靠拢。
- 特点:能保持拓扑结构(输入空间相邻的点,映射到 SOM 网格上也相邻)。
AP 聚类 (Affinity Propagation)
- 核心思想:所有点都想当老大(Exemplar),大家互相发消息(吸引度和归属度)来选举。
- 优点:不需要预设 值(这是最大的卖点),初值不敏感。
常用网络模型
本章节只有 2022 级教案有,2023 级的 V6 教案不存在这部分内容。
卷积神经网络(CNN)
DNN(全连接网络)在图像上有一个致命问题:参数量爆炸:例如, 100×100 ×3 的彩色图片,如果用全连接层输入:
100 × 100 × 3 = 30,000 个输入节点
如果下一层是 1000 节点,则需要 3千万参数
非常容易过拟合。
而 CNN 利用图像特性,能够减少参数:
局部连接,图像的模式(边缘、纹理)一般都很局部,不需要覆盖全图,所以卷积只连接像素的一个小邻域(如 3×3)。
参数共享,同一模式会在不同区域出现,所以使用同一卷积核扫描整张图,参数量不随图像大小增长。
下采样不改变物体,所以池化层(Pooling)减少分辨率,但保留关键结构。
CNN 的典型结构
graph TD
A[Input Image] --> B[Convolution Layer]
B --> C[ReLU]
C --> D[Pooling Layer]
D --> E[Convolution Layer]
E --> F[ReLU]
F --> G[Pooling Layer]
G --> H[Flatten]
H --> I[Fully Connected Layers]
I --> J[Output]
Convolution Layer -> Pooling Layer 可以重复很多次。
| 操作 | 目的 | 效果 |
|---|---|---|
| Convolution | 找局部模式(边缘、纹理、形状) | 提取特征 |
| Parameter sharing | 同一卷积核扫全图 | 降低参数量 |
| Pooling | 降低分辨率 | 提高鲁棒性 |
| Multiple filters | 不同通道学不同特征 | 多层次特征提取 |
卷积层(Convolution Layer)
卷积核心思想:边界检测(edge detection)、特征提取。
卷积核是一个小矩阵,例如(Sobel 核):
1 | |
每个卷积核扫描整张图,得到一个 特征图(feature map)。
多通道输出:使用 个卷积核,就得到 个通道,通道数 = 卷积核数量。
卷积减少尺寸(不使用 padding 时):
如果输入大小为:
卷积核为
输出大小为
池化层(Pooling Layer)
池化层的作用有:
- 下采样 → 降低分辨率
- 保留关键特征,使模型对小变化具有稳定性(translation invariant)
- 降低参数量、计算量
常用池化方式:
最大池化 Max Pooling(最常用):选出区域中最大值
平均池化 Average Pooling
池化不会改变通道数:它只改变宽高,不改变通道数量。
常用参数:
窗口大小 2×2、步长 2
意味着区域不重叠,尺寸缩小一半
Flatten 层
Pooling 后的输出形状为:
1 | |
Flatten 会把每个样本摊平为一个向量:
1 | |
然后输入到全连接层(分类器)。
经典 CNN 架构
LeNet-5(1998)
- 用于手写数字(MNIST)识别
- 第一篇“实用性” CNN 论文(Yann LeCun)
LeNet 架构流程:
graph TD
A[Input 32x32 Image] --> B[Conv 5x5, 6 Channels]
B --> C[Avg Pool 2x2]
C --> D[Conv 5x5, 16 Channels]
D --> E[Avg Pool 2x2]
E --> F[Flatten]
F --> G[FC 120]
G --> H[FC 84]
H --> I[FC 10 Classes]
AlexNet(2012)
推动深度学习爆发的关键模型
- 更深层
- 使用 GPU 训练
- 使用 ReLU
- 使用 Dropout
- 在 ImageNet 取得显著突破
VGG(2014)
特点:
- 使用简单的结构:连续的 3×3 卷积堆叠
- 深度更大(16 或 19 层)
优点:结构规则,方便迁移学习
GoogLeNet(2014)
使用 Inception 模块(并行多尺度卷积)
ResNet(2015)
- 使用 残差结构(Residual block)
- 解决深度网络梯度消失问题
- 可训练上百层甚至上千层
ImageNet 数据集
ImageNet(李飞飞团队):
- 1500 万图像
- 22,000 个类别
- 大规模标注
推动深度学习的两大动力:
- 大数据(ImageNet)
- GPU 计算能力
之后才有 AlexNet、VGG、ResNet 等模型的发展。
循环神经网络(RNN)
序列建模的核心困难,需要让 RNN 解决。
以往的前馈网络(DNN/CNN)满足的结构是:
Input → Algorithm → Output
每个输入只对应一个输出,没有记忆能力。
但在许多任务中:
- 句子(文本)
- 声音(语音)
- 视频帧序列
- 行为序列、时间序列(金融预测)
当前时刻的输入必须依赖之前的上下文,没有记忆能力的模型无法完成。所以需要 RNN —— 能把之前的信息保存下来。
RNN 的核心思想:“隐状态(hidden state)是记忆,它跟随时间不断更新”
单步结构:
1 | |
数学表达:
- 隐状态更新
- 输出
隐状态 同时依赖当前输入 ,也依赖历史状态 ,这就是 RNN 可以“记住前文信息”的原因。
RNN 的时间展开(unrolling)
展开后的结构:
graph LR
S0((S0)) --> A1[Cell t=1]
A1 --> A2[Cell t=2]
A2 --> A3[Cell t=3]
A3 --> A4[Cell t=4]
X1 --> A1
X2 --> A2
X3 --> A3
X4 --> A4
A1 --> O1
A2 --> O2
A3 --> O3
A4 --> O4
输入顺序不同 → 隐状态传递不同 → 输出也不同,所以RNN 是顺序敏感的模型。
RNN 的变种结构
双向 RNN(Bi-RNN)
普通 RNN:
- 只能看到过去 → 不看未来
对于句子理解来说:
- 当前词意义通常依赖前文和后文
所以有:
← RNN (看未来)
→ RNN (看过去)
拼接两者输出:
graph LR
X1 --> F1[Forward RNN]
X2 --> F2[Forward RNN]
X3 --> F3[Forward RNN]
X1 --> B1[Backward RNN]
X2 --> B2[Backward RNN]
X3 --> B3[Backward RNN]
F1 --> C1[(Concat)]
B1 --> C1
F2 --> C2[(Concat)]
B2 --> C2
F3 --> C3[(Concat)]
B3 --> C3
Deep RNN(多层 RNN)
把多个 RNN 叠在一起:
RNN layer 1 → RNN layer 2 → …
提高模型表达能力。
RNN 的三个主要缺点
- 短期记忆问题
只能记住最近输入,无法处理长序列
因为每一步都对记忆进行“覆盖” - 训练困难
RNN 的时间展开非常长,梯度要跨时间回传 - 梯度消失和梯度爆炸
不适合学习长期依赖
这也是为什么要有 LSTM、GRU
LSTM:解决长期依赖问题
LSTM(1997)引入 记忆单元(cell state) + 三个门:
- 输入门
- 遗忘门
- 输出门
公式如下:
LSTM 核心机制
- 遗忘门决定忘多少历史
- 输入门决定写入多少新信息
- 输出门决定输出多少记忆
梯度可以沿着 长距离传播,不容易消失。
GRU:更轻量的 RNN
比 LSTM 少一个门,更简单、训练更快。
GRU 结构:
- 重置门
- 更新门
- 候选隐藏状态
GRU 和 LSTM 效果相似,但参数更少。
Attention 机制
心理学基础:注意力是“选择信息子集、集中关注”的过程。
在深度学习中:Attention = 根据重要性对输入序列加权,让模型专注于更相关的部分。
好处:
- 解决 RNN 的长距离依赖问题
- 更好的信噪比,提高性能
- 可以解释模型关注了哪里
- 是 Transformer、BERT、GPT 的基础
Seq2Seq with Attention
RNN Seq2Seq 的问题:
- 编码器要把整个句子压成一个向量(太难)
- 会丢失大量信息
- 长句效果差
注意力机制:
- 解码器的每一步都使用编码器所有隐藏状态按权重加权
- “动态取信息”,而不是用一个静态向量
Self-Attention(自注意力)
这是 Transformer 的核心。
Q, K, V 模型:
- Q (Query):查询向量(我拿着这个去查)
- K (Key):键向量(被查的索引)
- V (Value):值向量(实际包含的内容)
计算过程:
- :计算相关性(相似度)
- :缩放因子(防止积太大导致 梯度消失)
- :归一化成概率(权重)
- 乘 :根据权重对 Value 进行加权求和
多头自注意力 Multi-Head Self Attention
一个头只能学习一种关系模式
例如:
- 语法依赖
- 主题相关
- 相邻词关系
- 长程依赖
多头注意力(Multi-Head Attention)让模型学多种模式。
做法:
- 把输入向量拆成多个子空间
- 每个子空间做一次 Self-Attention(称为一个“头”)
- 最后拼接(concat)各头的输出
- 再做线性变换
graph TD
A[Input Sequence] --> S1[Linear Q K V Projection for Head 1]
A --> S2[Linear Q K V Projection for Head 2]
A --> S3[Linear Q K V Projection for Head h]
S1 --> AT1[Self Attention Head 1]
S2 --> AT2[Self Attention Head 2]
S3 --> AT3[Self Attention Head h]
AT1 --> C[Concat]
AT2 --> C
AT3 --> C
C --> O[Linear Projection]
总结:
- 多头注意力 = 多种信息模式的组合
- Transformer 并行、高效、无序列依赖
图神经网络
CNN 只能处理网格数据(图片),RNN 处理序列数据。
但社交网络、分子结构、知识图谱这种图结构 (Graph) 怎么办?
图神经网络的核心思想:
- 邻居聚合 (Neighbor Aggregation):一个节点的特征,应该由它自己和它的邻居节点共同决定。
- 消息传递 (Message Passing):节点之间通过边交换信息,更新自己的状态。
GCN (图卷积网络)
简单理解:就是把 CNN 的卷积操作推广到了图上。
- 公式里通常涉及邻接矩阵 (表示谁和谁相连)。
神经网络
神经元模型
M-P 神经元模型
M-P 神经元模型是最原始的神经元模型。
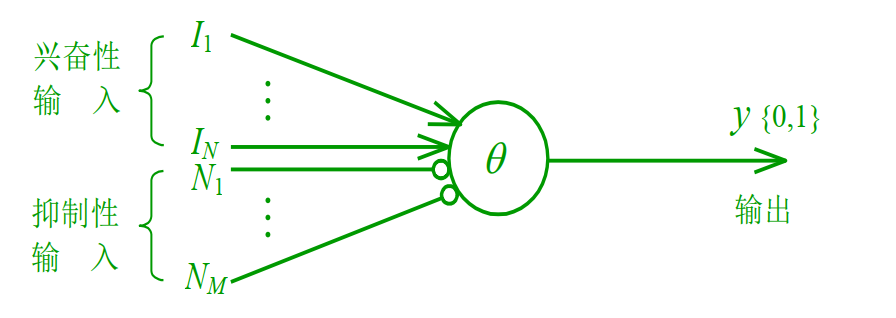
公式:
- :输入信号。
- :权重(连接强度)。
- :阈值(Threshold,也可以看作偏置 )。
- :激活函数(早期常用阶跃函数,现在常用 Sigmoid/ReLU)。
M-P 模型可以实现逻辑运算(与、或、非),但它没有学习能力(权重是人为设定的)。
感知机
感知机是具备学习能力的起点,它是一个单层神经网络。
能力:只能解决线性可分问题(如 AND, OR)。
死穴:无法解决 XOR(异或)问题。因为 XOR 是非线性的,一条直线分不开。
感知机 的损失函数:
学习规则:
- 物理含义:如果预测错了,就根据误差调整权重;预测对了就不动。
多层前馈网络 (MLP)
为了解决XOR问题,我们在输入层和输出层之间加入了隐层 (Hidden Layer)。
- 万能逼近定理:只要有隐层,且神经元够多,MLP可以逼近任意连续函数。
在多层前馈神经网络中,通用神经元的计算模型是:
其中,
- :来自上一层的输入
- :权重,可学习参数
- :偏置项,可学习参数
MLP 参数量计算
MLP 的参数量就是权重 和偏置项 的总数量,用于衡量模型的复杂度。
假设:
- 输入层节点数:
- 隐层节点数:
- 输出层节点数:
请务必记住:每一层都有偏置(Bias)!
- 输入 隐层:
- 权重数:
- 偏置数: (每个隐层神经元配一个偏置)
- 隐层 输出:
- 权重数:
- 偏置数:
- 总参数量 =
例子:输入10维,隐层5个节点,输出1维。
参数量 = 。
千万别漏了偏置!输入层不会进行计算!
反向传播算法
- 正向传播 (Forward Pass):输入信号一层层传过去,算出预测值 ,算出误差 。
- 反向传播 (Backward Pass):把误差 从输出层反向传回来,根据链式法则计算梯度,更新权重。
关键公式推导
以单样本、Sigmoid 激活为例。
- 输入 ,权重 ,偏置 。
- 线性输出 。
- 激活输出 。
- 损失函数 。
我们需要求: (误差对权重的梯度)
利用链式法则 (Chain Rule),像剥洋葱一样一层层剥开:
我们一项一项算:
误差对输出的导数 :
输出对输入的导数(Sigmoid导数) :
输入对权重和偏置项的导数 和 :
通常记为 ,叫做误差信号。
最终梯度公式(合并):
权重更新公式:
那怎么求隐藏层和更前面的层的更新?同样假设:
- 输入:
- 隐藏层(第 1 层):
- 线性部分:
- 激活输出:
- 输出层(第 2 层):
- 线性部分:
- 最终输出:
- 损失函数:
那么我们要求的就是梯度:
输出层部分我们已经求出来了:
因为 ,所以显然地,有
然后就很简单了,
整合一下,
激活函数
激活函数主要有:
- Sigmoid:
- 优点:输出在 之间,类似概率,平滑。
- 缺点:梯度消失问题(导数最大只有 0.25,深层网络传不回去)、非零中心。
- :双曲正切,
- 形状和 Sigmoid 差不多。
- 输出在 之间,零中心,比 Sigmoid 好,但依然有梯度消失。
- ReLU (Rectified Linear Unit):
- 优点:计算简单(只判断正负)、解决梯度消失(正区间导数为1)、收敛快。
- 缺点:Dead ReLU(负区间导数为0,神经元“死”了)。
神经网络的训练技巧
这部分主要针对“过拟合”和“难训练”。
过拟合 (Overfitting):
- 现象:训练集准确率极高,测试集很差(死记硬背)。
- 对策:
- 早停 (Early Stopping):验证集误差开始上升时,立刻停止训练。
- 正则化 (Regularization):在损失函数里加 或 范数(限制权重大小)。
- Dropout:随机让一部分神经元不工作,强迫网络不依赖特定神经元,增强鲁棒性。
数据预处理:
- 归一化:把输入数据压缩到 或 ,加速梯度下降收敛。
跳出局部最小的策略
- 多组不同的初始参数优化神经网络,选取误差最小的解作为最终参数
- 模拟退火技术,每一步都以一定的概率接受比当前解更差的结果, 从而有助于跳出局部极小
- 随机梯度下降,与标准梯度下降法精确计算梯度不同, 随机梯度下降法在计算梯度时加入了随机因素.
- 遗传算法
动量项
在标准的梯度下降(Steepest Descent)中,我们每次更新只看当前的坡度(梯度)。而动量项(Momentum) 的思想是:不但要看当前的坡度,还要看之前跑得有多快(惯性)。
批处理反向传播和随机反向传播
批处理 BP 算法 (Batch Gradient Descent, BGD):在每次更新权值之前,计算所有样本的误差
优点:
- 方向准:因为看了所有数据,梯度的方向是最准的(数学上的“最速下降”)
- 稳定:收敛曲线很平滑
缺点:
- 慢,效率极低
- 容易陷入局部最优(因为它太“理智”了,没有随机性)
随机/在线 BP 算法 (Stochastic Gradient Descent, SGD):每计算一个样本点的误差就更新权值一次,需将数据每个循环随机打乱
关键操作:随机打乱 (Shuffle)。这是为了防止数据有某种排序规律(比如先把简单的全学了,再学难的容易学崩),打乱后能保证学习的随机性和独立性。
优点:
- 快,参数更新频率极高
- 能跳出局部最优:因为单个样本的梯度可能有“噪声”(不代表整体),这种“乱走”反而可能误打误撞跳出坑
缺点:
- 震荡:更新路径像醉汉走路,晃晃悠悠,很难稳定在最低点
Mini-batch,既不是用所有样本,也不是用 1 个,而是每次用一小堆(比如 64 个)
- 优点:结合了 Batch 的稳定性和 SGD 的速度,而且适合 GPU 并行计算,是当前的主流
神经网络的局限性
- 神经网络由于强大的表示能力,经常遭遇过拟合。表现为:训练误差持续降低, 但测试误差却可能上升。
- 如何设置隐层神经元的个数仍然是个未决问题,实际应用中通常使用“试错法”调整。
径向基函数网络(RBF)
这一章是完全的非重点,看看概念即可。
径向基函数网络是一种局部模型,它不像全局模型(如 BP)那样牵一发而动全身,而是把输入空间划分成很多小区域,每个区域派一个专家(径向基函数)去负责。
RBF 网络的核心结构
RBF 网络非常简单,只有三层(输入、隐层、输出),而且结构是固定的:
- 输入层:是个传声筒,把数据 原封不动地传给隐层。
- 隐层:是 RBF 的灵魂。
- 功能:把低维的输入数据,映射到高维空间(类似于 SVM 的核函数思想)。
- 激活函数:径向基函数(Radial Basis Function)。最常用的是 高斯函数(Gaussian)。
- 特点:局部响应。这就好比在地图上插旗子(中心点),只有当走到旗子附近时,这个神经元才会“兴奋”起来;离得远了,它就没反应(输出为 0)。
- 输出层:就是一个简单的线性回归。把隐层那些“专家”的意见加权求和。
核心公式
高斯径向基函数(隐层输出):
- :你的输入数据。
- :第 个隐层神经元的中心(Center)。
- :扩展常数(宽度/方差)。它决定了这个“专家”管辖范围有多宽。
- 算出输入 和中心 的距离,距离越近,输出越接近 1;距离越远,输出越接近 0。
网络最终输出(线性组合):
- :权重。
- 把所有“专家”的打分 乘以它们的权威度 ,加起来就是最终结果。
RBF 和 BP(MLP)的对比
感觉是这一章唯一可能考的……
| 特性 | RBF 网络 (径向基) | BP 网络 (多层感知机) |
|---|---|---|
| 逼近方式 | 局部逼近 (Local) | 全局逼近 (Global) |
| 激活函数 | 高斯函数 (钟形曲线) | Sigmoid / (S形曲线) |
| 训练速度 | 快 | 慢 |
| 结构 | 固定三层 | 层数不限,结构灵活 |
| 泛化能力 | 较好,尤其在插值问题上 | 取决于结构和训练,容易过拟合 |
- 局部逼近 (RBF):一个神经元只对输入空间的一小块区域有反应。修改一个神经元的参数,只影响这一小块区域的输出,对其他地方没影响。
- 全局逼近 (BP):Sigmoid 函数在定义域内无限延伸。修改一个神经元的参数,会影响整个输入空间的输出结果(牵一发而动全身)。
训练算法
RBF 网络有三个参数要定:中心 、宽度 、权重 。训练通常分两步,这就是它快的原因:
无监督学习:找中心 和宽度 。
- 不用管标签 ,只看输入数据 怎么分布。
- 方法:可以用 K-Means 聚类,聚出来的 个簇中心,就是 RBF 的 个隐层中心。
- 宽度 通常设为中心点之间的最大距离或者平均距离。
有监督学习:找权重 。
- 一旦中心和宽度定好了,隐层的输出 就是已知数了。
- 这时候网络就变成了一个简单的线性回归模型:。
- 方法:直接用 LMS (最小均方算法) 或者 伪逆法 (正规方程) 一步算出最优权重 。不需要像 BP 那样迭代。
正则化 RBF
- 完全内插法:如果在每个样本点上都放一个高斯函数(中心就是样本本身),那么训练误差就是 0。
- 问题:这样做模型太复杂,容易过拟合(对噪声敏感),而且参数太多计算量大。
- 解决:广义 RBF。中心点个数 远小于样本数 (),不再每个点都放中心,而是选几个代表性的点(聚类中心)放中心。这本质上就是一种正则化思想。
参考和注解
参考,也可以看一看:
- 陈学长整理的资料
- 猫娘学长的 2022 级考试真题回忆
- 饭哥整理的速成
- 教材:李航的统计学习方法及它的习题,这本书其实讲得很好,比教案好 倍
- 统计学习方法习题解答,有些题可能可以看
注释
- 便于求导,使导数中前面的系数变得更整齐。 ↖
- 即一个数学问题的解可以用有限次的标准数学运算直接表达出来,不需要迭代、极限、数值方法等过程。 ↖
- Perceptron,也是一种二分类线性分类模型,本质上跟神经网络的感知机模型是一个东西,只不过神经网络的是原始感知机的推广。通过 得到分类结果。 ↖
- 指的是范数,例如 指的就是 系数的平方 ↖
- 超平面是一个几何概念,用于描述高维空间中的一个子空间,它将空间分割成两个部分。超平面的定义和维度依赖于它所在的空间的维度。例如在三维空间中,超平面是一个二维平面。它可以分割空间,且通过原点。 ↖
- 统计学习方法第 531 页,附录 C 拉格朗日对称性。 ↖
- 统计学习方法第 103 页,这部分的所有证明基本都是来自这里。 ↖
- 如果 很大,那么就很管道窄,回归线陡,所以模型容易“过拟合”,对噪声敏感。从结构风险最小化的角度看 ,我们要让间隔最大,等价于最小化模型复杂度,也就最小化了过拟合风险。 ↖
- 求均值就是把这些样本在每个维度上的值求平均,得到一个新的点,然后这个点就是新的质心。例如二维的样本点 ,它们组成的簇的均值/质心就是 。 ↖